

Achieving ACID Transactions in a Globally Distributed Database
One of the features of Fauna that has generated the most excitement is its strongly consistent distributed ACID transaction engine. In this post we’ll explain how Fauna’s Calvin-inspired transaction engine processes ACID transactions in a partitioned, globally distributed environment, and how you can take advantage of them in your applications.
Why ACID Transactions Matter
ACID transactions are a powerful tool because they guarantee that operations behave the way developers expect:
A system with ACID transactions makes a promise that data integrity will be preserved even under contention and faults such as node failure and network partitions.
Formally, ACID refers to a set of properties a database system maintains during transaction execution. These properties are:
- Atomicity: Transactions are indivisible units, such that all of their effects apply, or none of them do.
- Consistency (or Correctness): Transactions are only allowed to apply if they do not violate database constraints such as uniqueness or schema constraints. Not to be confused with CAP Consistency, below.
- Isolation: The degree to which one transaction’s effects are visible to another transaction. Most systems talk about isolation in terms of a number of isolation levels, discussed in more detail below.
- Durability: A transaction that is committed is permanent and will survive expected faults such as power loss or node failure.
Until recently, however, ACID transactions haven’t been feasible in the context of globally scalable web applications. The assumption has been that the only options beyond a certain scale are to either sacrifice consistency, or to somehow partition application data and limit operations to those that can be handled by a single partition.
Conditional Updates
Here’s a concrete example of an operation that is trivial to implement with ACID transactions, but difficult to do otherwise. Consider an online game which allows players to buy and sell in-game items. The application needs to enforce two rules:
- A buyer can only purchase an item if they have enough currency
- The item must actually be for sale
In this example, player records have a “credits” field which stores the number of credits available for them to spend. Here is an example player represented by a Fauna query DSL snippet:
Obj(
"ref" -> Ref(Class("player"), 43254525535),
"ts" -> ...,
"data" -> Obj("credits" -> 40)
)And along with it, an item:
Obj(
"ref" -> Ref(Class("items"), 1291723917),
"ts" -> ...
"data" -> Obj(
"description" -> "Green Polliwog",
"owner": Ref(Class("players"), 69329839),
"for_sale": true,
"price": 35
)
)When an item is sold, the buyer, seller, and item are updated, and a purchase record is created, only if our rules above hold. (Sometimes this form of conditional update is informally referred to as “compare and swap”.)
The following Fauna query processes the sale:
Let {
// look up the buyer and item instances.
val buyer = Get(Ref(Class("players"), 43254525535))
val item = Get(Ref(Class("items"), 1291723917))
val seller = Get(Select("data" / "owner", item))
val buyerRef = Select("ref", buyer)
val sellerRef = Select("ref", seller)
val isForSale = Select("data" / "for_sale", item)
val itemPrice = Select("data" / "price", item)
val buyerCredits = Select("data" / "credits", buyer)
// ensure the buyer and seller are not the same player
If(Equals(buyerRef, sellerRef),
"purchase failed: item already owned",
// check to see if the item is for sale
If(Not(isForSale),
"purchase failed: item not for sale",
// check the buyer credit balance
If(LT(buyerCredits, itemPrice),
"purchase failed: insufficient credits",
// all clear! record the purchase, update the buyer, seller, and item.
Do(
Create(Class("purchases"), Obj(
"data" -> Obj(
"item" -> Select("ref", item),
"price" -> itemPrice,
"buyer" -> buyerRef,
"seller" -> sellerRef
)
)),
Update(buyerRef, Obj(
"data" -> Obj(
"credits" -> Subtract(buyerCredits, itemPrice)
)
)),
Update(sellerRef, Obj(
"data" -> Obj(
"credits" -> Add(Select("data" / "credits", seller), itemPrice)
)
)),
Update(Select("ref", item), Obj(
"data" -> Obj(
"owner" -> buyerRef,
"for_sale" -> false
)
)),
"purchase success"
)
)
)
)
}As you can see, the logic for the purchase is neatly encapsulated in a single query. Moreover, the results of the transaction are made consistently available to clients such that the entire result is seen at once.
Resolving this kind of purchase logic in a distributed environment without transactions is much more involved. It is up to the developer to identify and handle data in various inconsistent states as well as the specific faults made possible by the architecture they have implemented, and a lot can go wrong. A set of formal guarantees like ACID is much easier to reason about.
The only other option would be to manually shard the application into multiple silos, each backed by a traditional, non-distributed RDBMS. This significantly limits the capabilities of the application, and is unworkable in a product where users expect to be able interact with each other without restrictions.
ACID in Fauna
The challenge of implementing ACID transactions in a distributed system comes down to consistently resolving transactions across data partitions in as efficient and scalable a manner as possible. Furthermore, with geographically distributed replicas, minimizing cross-region network communication is critical in order to maintain reasonable response latencies.
Fauna’s distributed transaction engine is inspired by Calvin. Each database has a single partitioned RAFT-replicated log that is used to derive a total order of all transaction effects, and that handles all cross-region network communication.
Transactions are processed in two phases: an execute phase and a commit phase.
In the execute phase, the node which received the client’s query (called the “coordinator node”) executes the core transaction logic, dispatching reads to the closest available data partitions and accruing write effects. Before doing so however, the coordinator chooses a snapshot time with which to make all read requests. This snapshot time is chosen in coordination with the transaction log in order to prevent stale reads. Data partitions respond to reads as they are able to, and will delay or drop reads until they are caught up to the time chosen.
If transaction execution accrues any write effects, then the process will enter the commit phase. Along with actual values, prior read results include last update timestamps which act as optimistic lock acquisitions. These read timestamps along with the set of write effects are committed to the database’s transaction log. The transaction is then assigned a logical transaction time based on the order in which its effects are added to the log.
While this transaction time ultimately reflects the causal ordering of a transaction with respect to others, it corresponds closely to real-time as well depending on system clock accuracy. This gives Fauna the nice characteristic of having reasonably accurate transaction timestamps which still reflect causal relationships between transactions without relying on synchronized, exotic time sources such as atomic or GPS clocks.
At this point, transaction resolution proceeds in parallel across the database’s data partitions. This approach to transaction resolution allows Fauna to provide a strong guarantee of strict serializability while still allowing for perfect processing parallelism in the absence of contention among transactions.
A transaction is considered committed and its write effects durably written to disk if no concurrent write to any read values has occurred. The set of optimistic read locks collected previously are checked, and if any concurrent modification is detected, this commit attempt will fail and the coordinator will retry the transaction or abort if it has timed out.
ACID and CAP
It is worth taking a moment to discuss the relationship between ACID transaction properties and the CAP theorem: Strictly speaking a system which supports ACID transactions must choose some form of consistency as framed by CAP.
There has been quite a bit of recent discussion surrounding CAP and the tradeoff between consistency and availability. While out of scope for this post, we agree with Daniel Abadi and Eric Brewer that industry experience has taught us that availability—in the strict sense that it is defined in the CAP theorem—is overrated: In practice, the uptime of systems that favor availability have not proven greater than what can be achieved with consistent systems.
More on Isolation Levels
Of the four ACID properties, Isolation has the most significant impact on the specific details of transaction resolution. Unlike the other properties, isolation is not a binary choice. Therefore, most systems—including Fauna—allow for some tradeoff between performance and a strict guarantee of isolation.
Isolation is usually discussed in terms of a set of isolation levels which each correspond to a set of write phenomena that are allowed to occur. These write phenomena are each a defined way in which concurrent transaction resolution is allowed to violate transaction isolation.
Since read-only transactions in Fauna always have a specific snapshot time but are not sequenced via the transaction log, they run at snapshot isolation, which for read-only transactions is equivalent to serializable.
Read-write transactions in Fauna where all reads opt in to optimistic locking as described above are strictly serializable. Transactions that are strictly serializable combine the behavior of serializability with linearizability: Strictly serializable transactions have a global, non-overlapping order with respect to each other, and this order corresponds to real time.
(As opposed to instance reads, index reads can be opted in or out of the optimistic lock mechanism, which affects the isolation level of involved transactions. This is discussed below)
In other words, for two strictly serializable transactions A and B, if the response for A is received before B is sent, then B will see the effects of A. This is a higher level of isolation than what is usually discussed in database literature, but is relevant in a distributed context that does not have the capability to coordinate via a shared sense of time.
As an example, consider a read-only transaction that happens after a read-write transaction, but with a stale snapshot time. The two transactions are still serializable, but as this would violate linearizability, they are not strictly serializable.
The reason why all transactions are not strictly serializable is for better read performance. In order to have a hard guarantee of strict serializability, all read transactions would need to involve the database transaction log, requiring a global message exchange in the process. This would result in read-only transactions taking 50-200 milliseconds at minimum. By relaxing the transaction isolation level for reads, they can be served by the closest available data replica and avoid a costly round of global communication.
There is usually no observable difference between the two isolation levels in practice. Regardless of whether read-only transactions were strictly serializable or not, subsequent writes are better off protected by a conditional check in order to guard against concurrent updates.
Indexes and Write Skew
As mentioned above, index reads within a read-write transaction skip the optimistic lock check. By skipping this check, index terms which receive a high number of writes (such as an index of all instances in a class) avoid the negative performance of a highly contended optimistic lock. However, this means that by default index reads are done at snapshot isolation and so subject to a specific write phenomenon called write skew.
Here is a practical example of what this means and how it can affect an application.
Let’s say that you are using Fauna to implement a todo list app. Tasks are created with a sequential index that is used to maintain the list order. Our task instances looks like this:
Obj(
"ref" -> Ref(Class("tasks"), 581234928),
"ts" -> ...,
"data" -> Obj(
"index" -> 1,
"list" -> "Groceries",
"description" -> "Buy Tomatoes"
)
)We’ve created an index that represents lists of tasks. Tasks within a list are sorted in descending index order, so that by default new tasks show up at the top of a list:
CreateIndex(Obj(
"name" -> "tasks_by_list",
"source" -> Class("tasks"),
"terms" -> Obj("field" -> Arr("data", "list")),
"values" -> Arr(
Obj("field" -> Arr("data", "index"), "reverse" -> true),
Obj("field" -> Arr("data", "description")),
Obj("field" -> "ref")
),
))Our query to add a new task is pretty straight-forward:
Let {
// Get the Groceries list.
val list = Paginate(Match(Index("tasks_by_list"), "Groceries")
Let {
// get the index from the first item in our page,
// or 0 if it was empty.
val last_index = Select(0 / 0, Take(1, list), 0)
// Add our new item. Generate the next index
// value by incrementing the last one.
Create(Class("tasks"), Obj(
"project" -> "Groceries",
"index" -> Add(last_index, 1),
"description" -> "Buy Bananas"
))
}
}However, there’s a problem: If two new tasks are added concurrently, they may end up with the same index, which is not what we want. Here’s how the two creation transactions can sequence with each other that shows how it can happen:
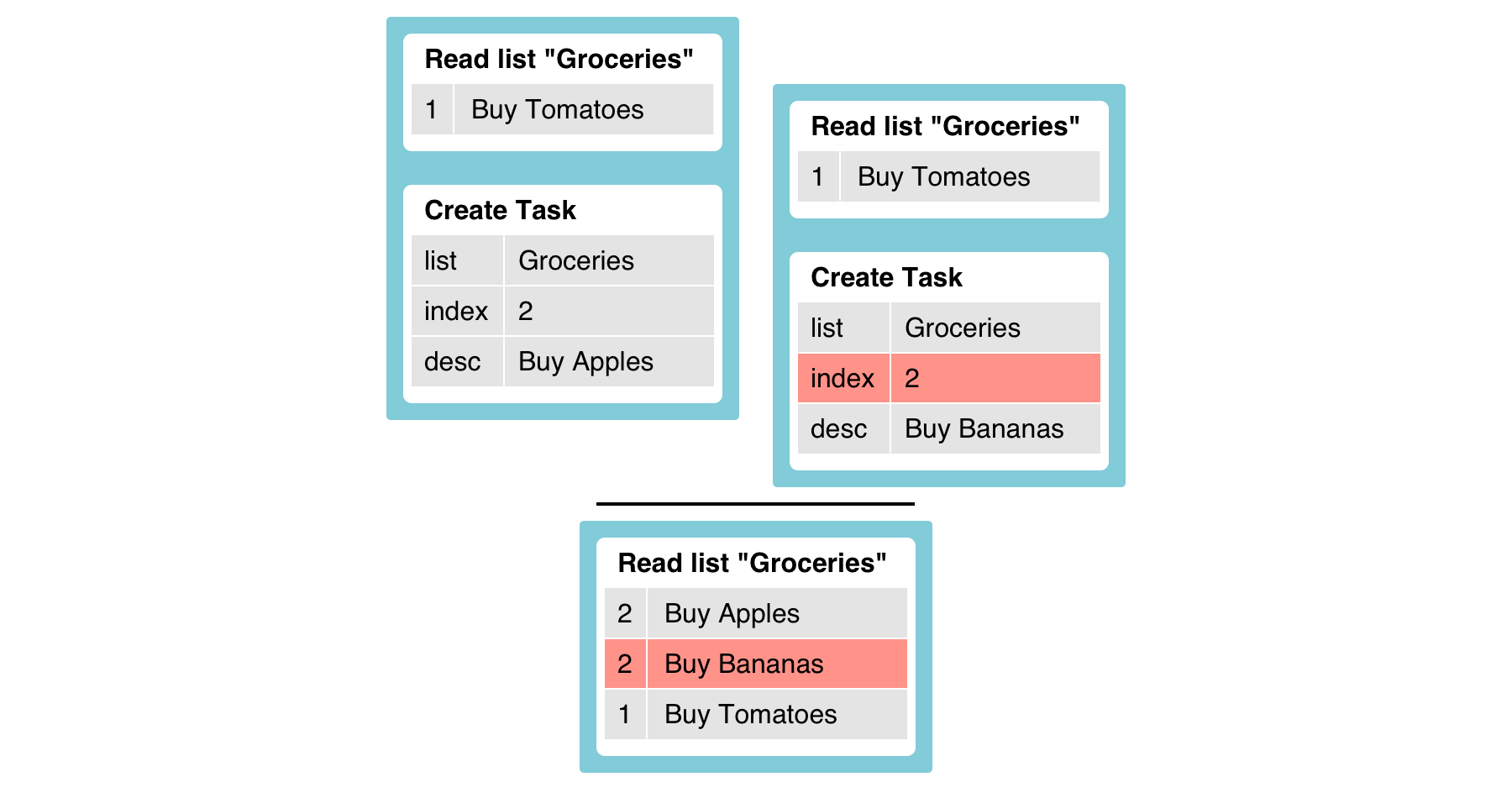
The second transaction reads the same state of the list, but because concurrent modifications to the list are not checked for, it successfully creates a new task “Buy Bananas” with a conflicting index value.
Solving this is just a matter of flipping a switch on the index configuration so that its state is opted into concurrent modification detection:
Update(Index("tasks_by_list"), Obj("serialized" -> true))Now our query above will work as expected. The update to the list is detected and the second transaction is retried in order to preserve strict serialization:
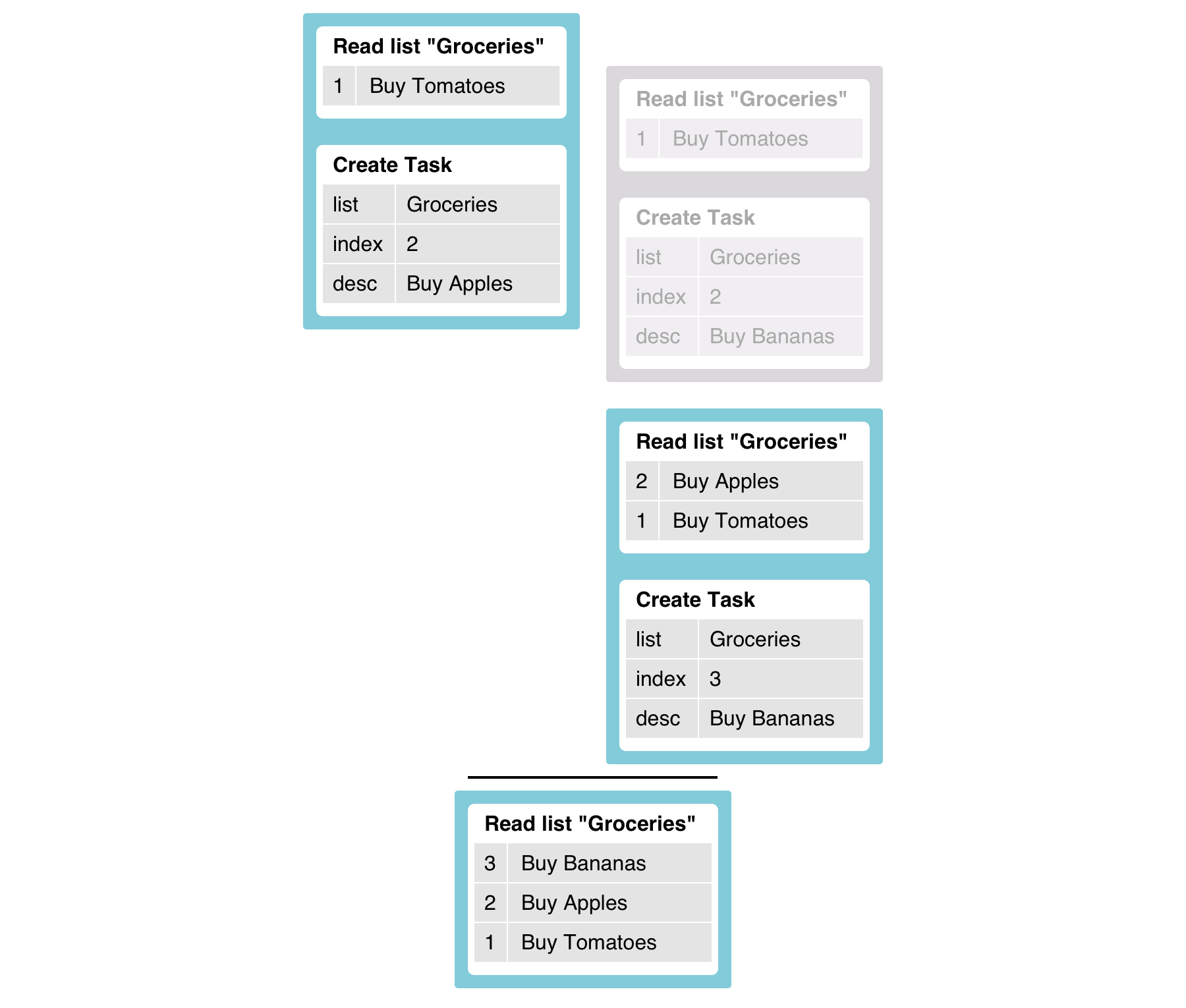
Conclusion
In this post we described how distributed ACID transactions work in Fauna, as well as why they are an essential building block for applications. In the end, we consider them and strong consistency to be table stakes for any modern, distributed database.
Fauna’s transaction support is the foundation for many of its other features, such as temporality, global distribution, low-latency consistent reads, and operational resiliency. You can learn more about the architecture of Fauna in our architectural white paper.
You can also sign up for an account and try Fauna for yourself.
If you enjoyed our blog, and want to work on systems and challenges related to globally distributed systems, serverless databases, GraphQL, and Jamstack, Fauna is hiring!
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.