


Live UI updates with Fauna’s real-time document streaming
Real-time application features have silently become omnipresent in our everyday life in the form of instant messaging, real-time statistic updates, or collaborative editing. They have moved from a ‘nice to have’ feature to, in some cases, the determining factor whether my new application will be perceived better than the one from a competitor.
That said, Fauna has always had a strong story to keep applications in sync or retrieve updates since temporality is a first-class citizen. The standard temporality features already provided you with the means to travel back in time, change history, and functionality to easily retrieve events. Fauna already supported the following event retrieving functionalities that could be combined to support “live” updates in a pull-based fashion.
But first, let’s take a look at the existing features before we dive into streaming and explain the difference.
Set events
When it comes to retrieving data updates, Fauna always provdied the ability to retrieve
add and remove events from a set of documents such as a collection or index or by simply specifying events: true as an option upon paginating the result. var tweetSet = Documents(Collection("tweets"))
Paginate(tweetSet , {
events: true,
after: Time("2020-05-22T19:12:07.121247Z")
})Document events
Similarly, Fauna has allowed us to
create,delete, and update events from a specific document.Var tweetRef = Ref(Collection("tweets"), '233555580689580553')
Paginate(tweetRef ,
events: true,
after: Time("2020-05-22T19:12:07.121247Z")
)Combining set and document events to pull for changes
With an extra index (in this case
tweets_after_ts), the power of FQL, and some clever tinkering, we could combine these into one FQL statement to retrieve all document events updates after a given timestamp as described here.Map(Paginate(
Range(
Match(Index("tweets_after_ts")),
ToMicros(Time("2020-05-22T19:12:07.121247Z")),
null
)
),
Lambda(['ts', 'ref'], Paginate(Var('ref'),
{events: true, after: Time("2020-05-22T19:12:07.121247Z")}))
) By using such a function receive fine-grained updates on what has changed in our data. However, since the client has no idea when there will be an update, the client needs to ask for an update periodically. Depending on the pulling frequency, the user would experience this as “live” streaming.
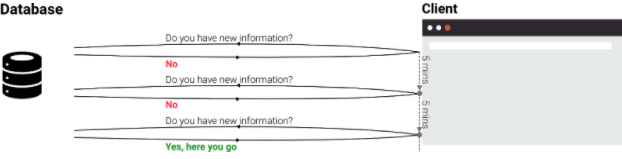
Of course, in such a polling approach we will often run queries that yield no results. Although we can poll very cheaply thanks to the temporality features in Fauna, we will still waste some read operations as well as network bandwidth and client CPU. When we want to provide our users with a real-time experience, we need to increase the polling frequency dramatically which will consequently increase the number of wasteful calls.
Nevertheless, such a pull-based approach is a common approach of many libraries that claim offer streaming, resulting in hidden costs to the user. When we are looking for real-time data, as live as it can possibly be, we can do much better with true push-based streaming features.
Push-based streaming brings true live-streaming at an affordable price.
Push-based streaming brings true live-streaming at an affordable price.
Since Fauna offers strong temporality features, many have asked whether Fauna is a real-time database. Although real-time was already achievable by using the aforementioned features, Fauna now provides a better and easier alternative for live user interfaces by introducing true push-based streaming.
The new streaming features change the interaction pattern with the database completely. Instead of polling for changes, the database is now capable of informing the client when a document is updated. This allows a client to subscribe to events and be informed by the database of new updates. This greatly reduces the number of communication and potentially wasted read operations. Most importantly, the delay between an applied write-transaction and the arrival of this new information in the relevant clients becomes minimal.
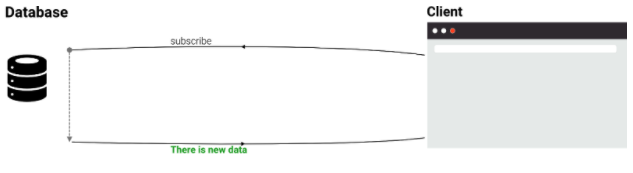
As a result, Fauna users can implement truly live interfaces with minimal effort and zero overhead.
Using the streaming API in your own app
Let’s take a look at how we can set up document streams and take advantage of the new functionality.
Defining the stream
The drivers now contain a new streaming API which allows you to subscribe to document events easily. For example, in JavaScript, we would install the latest version of the driver as follows:
npm install faunadb Streaming is supported starting from the JavaScript driver version 4.0.0. To create a streaming client, start with the
client.stream.document() function:var client = new Client({secret: <secretOrToken>})
var stream = client.stream.document(ref)
.on(‘start’, (data, event) => ...)
.on('snapshot', (data, event) => ...)
.on('version', (data, event) => ...)
.on('history_rewrite', (data, event) => ...)
.on('error', (data, event) => ...)As can be seen from the above, we have the option to subscribe to different events:
start: a stream subscription always begins with a start event that includes a timestamp. Other events on this stream are guaranteed to have timestamps equal to or greater than this event.
snapshot: the initial document when you start the stream. This event provides you with the current state of the document and will arrive after the start event and before other events.
version: when the data of the document changes, a new event will arrive that details the changes to the document.
history_rewrite: a notification when history is rewritten which serves as a notification to indicate that you should restart the stream as the current stream might no longer reflect reality due to a history rewrite.
This is regardless of whether the history rewrite is a new event that comes after the last document state, whenever you use Fauna’s history functions such as Insert() and Remove() this event will be triggered.
errors: listen for errors.
Starting and closing the stream
Until we start the stream, we will not receive events so let's start the stream by calling the
start() method we will start receiving events. stream.start() When the stream starts, we will immediately receive the start and snapshot events. Once we adapt the data of a document, e.g. via the Fauna dashboard, the version callback is triggered which provides us with information about the update. Typically, when you receive a history_rewrite or error event you will want to restart the stream for that specific document since you can no longer guarantee that the local version of your document is still up to date.
When the stream is no longer necessary, calling the
close() method will release any underlying held connections. subscription.close()Restarting a stream, e.g. upon an error, would be done by closing it down, waiting for a short period, then recreating the stream from scratch as shown in the JavaScript driver docs.
Extra options to select your desired event data
Upon defining a stream the driver includes an optional parameter that allows you to specify exactly which event data you want to receive. For example, instead of retrieving the current document, this allows you to retrieve the convenient diff field that provides you with the calculated difference and/or the prev field which provides you with the previous state of the document so you can calculate the difference yourself. By default, events contain the action and
document field. client.stream.document(<a document reference>,
{ fields: [‘document’, ‘prev’, ‘diff’, ‘action’]}
)Using the streaming API in an example app
To help you get started, we have provided an example application that can be found here. Since streaming can be applied to many use cases, the application stays very generic. Instead of implementing a specific use case, the example allows you to paginate through a collection of documents of your choice and will open streams for each of the documents that are visible in the current page. Once you start editing these documents, you will see the incoming updates visualized for the current page. The application combines pagination with streaming to show how a page with documents can be opened and remain live as well as how to reclaim streams and open a new set of streams.
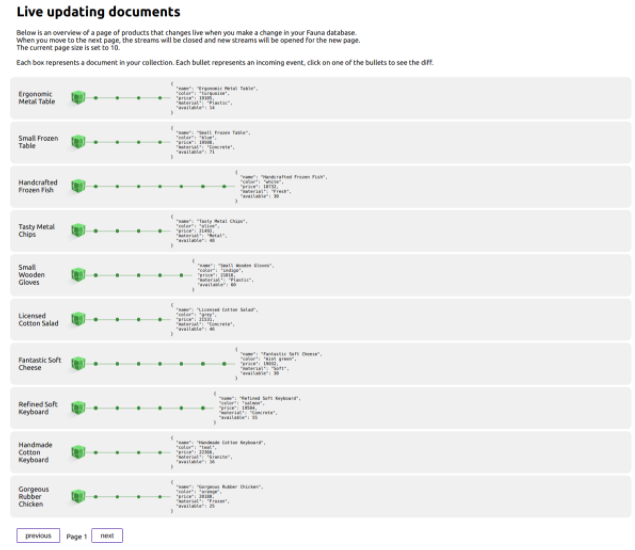
When going to the next page, the streams of the current page will be closed and the next set of streams will be opened for the next page. Watch this short video that shows you how it works.
We have provided two scripts to populate and update data so you can set it up and see it in action in a matter of minutes.
Streaming vs. polling
With the introduction of an extra feature, we might wonder when to use streaming and when to use polling. This question typically comes down to the data requirements and pricing. Streaming will be billed per minute (for which the future pricing can be found here) whereas you incur read operations per query when you use polling. In the case of polling, the frequency that you will run the query with will determine the liveliness of your data and the price. Streaming on the other hand offers the lowest possible latency to deliver new data at a fixed price per minute. As the polling frequency goes up, there is a point where streaming becomes more efficient. For a given set of data, you can easily calculate this point by verifying the read operations of one query and then extrapolating the price in case you would be running this query periodically for a long period.
It doesn’t have to be one or the other; streaming and polling might have use cases in the same application. Since Fauna is not opinionated and offers both, you could open streams for data that has to be real-time and use temporality-based polling for data that is less likely to change or for which you know that it will change based on an event from another system in your application.
How does it work under the hood?
For those who like to look under the hood, there is quite some terminology and comparisons to be found on various streaming implementations such as XHR, Sockets, SSE, HTTP2. For Fauna’s document streaming, we were looking for a modern approach that provides a lightweight multiplexed connection that works well over most networks. HTTP/2 achieves exactly that and in comparison to other approaches is generally less resource expensive from an infrastructure perspective. Fauna streams are implemented on top of HTTP/2 streams which means that the client (browser or development environment) ideally supports HTTP/2 to use Fauna streaming. Although Fauna’s streaming works with HTTP/1.x, if your environment supports HTTP/2 it becomes much more efficient.
Next steps
Fauna’s streaming features are implemented in multiple phases for which the first phase, Document Streaming is now available and introduced in this article. Collection and index streaming are further on the roadmap, but we can already do amazing things by opening multiple document streams, especially when we combine it with other temporality features. For example, we could periodically poll a collection or index to see if there are new documents or deleted documents and open document streams from the moment we receive these references.
Currently, there is a limit of 100 streams per client which should be able to support a wide range of use cases.
Conclusion
Although document streaming is only the first phase, it adds a lot of convenience to update UIs. You no longer have to keep track of timestamps and periodically call event queries to retrieve updates after that given timestamp. Besides the convenience, streaming can potentially save read operations and avoid wasted resources while delivering updates with an unbeatable low latency.
To learn more about document streaming, more information can be found in the documentation on the current limitations and how billing will work in the future.
If you enjoyed our blog, and want to work on systems and challenges related to globally distributed systems, serverless databases, GraphQL, and Jamstack, Fauna is hiring!
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.