


Modernizing from PostgreSQL to Serverless with Fauna Part 3
Brecht De Rooms|Feb 22nd, 2021
Introduction
In the previous chapters, we extended our query and transformed it into separate composable sub-queries. In this chapter, we’ll answer a number of questions that might come up when reading through the previous chapters or coming from a traditional database. Questions about referential integrity, optimizations, trade-offs in modeling strategies, etc. We’ll see how we can take further advantage of building application specific languages, take advantage of User-Defined Functions to manage implicit schemas more effectively, and even define our own schema validator.
Referential integrity
Although Fauna does support uniqueness constraints, many databases have first-class support for more advanced constraints such as foreign keys and cascading referential actions to ensure referential integrity. Advocates for scalable databases typically say that referential integrity doesn’t scale, while advocates for traditional databases will strongly advise you to use them since integrity is more important than speed. Performance in traditional databases can even benefit from foreign keys since the query planner can use them to optimize execution plans.
The reality is probably more subtle. In most cases, the overhead of foreign keys is offset by the optimization advantages, but if that’s not the case, the performance impact can definitely be noticeable (especially if one forgets to place indices on foreign keys). A potential pitfall where it can become a bottleneck is when a highly connected item has to be deleted. Having cascading deletes in place could trigger a chain reaction that results in a very slow query and a big transaction; the bigger your data grows, the bigger the risk.
First, Fauna would not benefit from the potential performance gain since for price and performance predictability, the procedural query equals the query plan. Due to a potential chain reaction, supporting cascading referential actions in a scalable database can indeed be quite delicate. Fauna makes sure that transactions stay relatively small and the introduction of cascading deletes could circumvent these efforts. Although we could prematurely kill the transaction if it runs too long, it would not be a great user experience if a delete functionality works fine and suddenly stops working due to an increase in data size. Therefore, at this point, Fauna does not provide foreign keys and cascading referential actions. But does that mean you need to abandon data integrity? No! As you would expect from a database that provides ACID guarantees, we believe that data integrity is crucial. Let’s take a look at possible ways that you could ensure integrity within FQL.
Verifying existence
Verifying the existence of a reference or set of references is easy. In the previous sections we created links between films and categories but didn’t verify explicitly whether these references exist.
Create(Collection("film_category"), {
data: {
category_ref: Ref(Collection("category"), "288805203878086151"),
film_ref: Ref(Collection("film"), "288801457307648519")
}
}),Instead, we could write a small helper:
var VerifyReference = (ref) => If(
Exists(ref),
ref,
Abort("Reference no longer exists")
)
Create(Collection("film_category"), {
data: {
category_ref: VerifyReference(
Ref(Collection("category"), "288805203878086151")),
film_ref: VerifyReference(
Ref(Collection("film"), "288801457307648519"))
}
})Providing an illegal reference would now abort the transaction. Slowly but surely, we are building our custom wrapper which radically reduces potential data errors. Of course, we can still do much better.
Cascading deletes
We can support cascading deletes to a certain extent by leveraging FQL. We could write a generic function that takes a reference to a document and deletes linked documents based on an index. Of course, we don’t always need an index but let’s assume we do to keep it simple.
var CascadingDelete = (entityReference, indexToLinkedEntity) => {
return Let({
linked_entities: Paginate(
Match(Index(indexToLinkedEntity), entityReference),
{size: 100000}
),
afterCursor: Select(["after"], Var("linked_entities"), null)
},
Do(
Delete(entityReference),
Map(Var('linked_entities'), Lambda(['linked_ref'],
Delete(Var('linked_ref')))
),
Var('afterCursor')
)
)
}Instead of using the regular Fauna Delete(), we can now use the CascadingDelete() and provide an index. We could also write a recursive version in case the cascading delete ranges over multiple relationships. We won’t risk triggering millions of deletes since pagination protects us from that. Finally, instead of returning the deleted entities, we will return either the after cursor or null. As long as the number of cascading deletes remains lower than 100000, everything is fine. If it exceeds that number, our application will receive an after cursor, and it can take action to remove the remainder in an asynchronous fashion.
Advanced transactions
Instead of creating all documents separately, we can write a function that creates a film and links the new film to the corresponding categories. First, let’s write a snippet to create a film.
var CreateFilm = (filmData) =>
Create(Collection("film"), {data: filmData})Next, let's get a category by name. Since we’ve used Get on the index match, it will throw an error if the category does not exist, aborting the entire transaction in which we use this snippet. We could easily change that later by checking for existence and then creating it if it doesn’t exist.
var GetCategoryName = (name) => Get(Match(Index("category_by_name"), name))Finally, given the film reference and category reference, create the “film_category” document that links both together.
var CreateFilmCategory = (fRef, cRef) => Create(Collection("film_category"), {
data: {
category_ref: cRef,
film_ref: fRef
}
})Then we can combine these functions to create a film, which will look up the categories and automatically create the documents that link the films with their corresponding categories:
var CreateFilmWithCategories = (filmData, categories) => Let(
{
film: CreateFilm(filmData),
filmRef: Select(['ref'], Var('film'))
},
Map(categories, Lambda(['name'],
Let({
category: GetCategoryName(Var('name')),
categoryRef: Select(['ref'], Var('category'))
},
CreateFilmCategory(Var('filmRef'), Var()))
))
)Which now allows us to write our film creation in a more sane way.
CreateFilmWithCategories(
{
title: "Academy Dinosaur",
language: {
spoken: { name: "English" },
subtitles: { name: "English" }
}
},
["Horror", "Documentary"]
)By changing one function, we can now create the categories if they don’t exist yet.
var GetCategoryName = (name) => Let({
categoryMatch: Match(Index("category_by_name"), name)
},
If(
Exists(Var('categoryMatch')),
Get(Var('categoryMatch')),
Create(Collection("category"), {data: {name: name}})
))Similarly, we could implement Upserts. Of course, this essentially makes our schema live implicitly in our code repository. Although that’s a first step, there is a better way by using User-Defined functions.
Implicit schemas
Storing the queries in User-Defined Functions (UDFs)
Instead of defining an explicit schema, our schema now lives in our application code. A query that lives in code could be changed accidentally, and developers might sometimes need to run queries manually. If we later on change the logic, we also want to make sure our code rolls out simultaneously everywhere which probably isn't guaranteed if you have multiple services or are retrieving data directly from a client with a cache (which becomes feasible if your database is a secure API).
Therefore, it makes much more sense to ensure that the explicit schema lives in the database itself. Instead of relying on our application code, we can store these queries in User-Defined Functions (UDFs) which is done with CreateFunction(). The following code snippet would store our logic in a function.
CreateFunction({
name: 'create_film_with_categories',
body: q.Query(
q.Lambda(
['filmData', 'categories'],
CreateFilmWithCategories(Var('filmData'), Var('categories'))
)
)
})Which then allows us to call it via:
Call(Function("create_film_with_categories"), {
title: "Academy Dinosaur",
language: {
spoken: { name: "English" },
subtitles: { name: "English" }
}
},
["Horror", "Documentary"]
)Functions encapsulate the logic atomically which also allows us to specify Fauna roles that only provide access to a specific function. This approach dramatically reduces human error when schemas are implicit.
Explicit schema in FQL
Function composition brings endless possibilities. In our second Auth0 article we showed generic FQL functions to interpret Auth0 roles, nothing stops us to write a function which we can plug in on every write that validates a schema. It’s still not as safe as a schema enforced by the database, but it does provide you with an incredible flexibility to mix and match schema with schemaless. When we wrote the )CreateFilmWithCategories(), we nicely factored out the functions that are responsible for creating categories and films.
Starting from our previous CreateFilm() and CreateFilmCategory(), we can now write a simple function to incorporate a schema. Let’s take CreateFilm() as an example which currently looks as follows:
var CreateFilm = (filmData) =>
Create(Collection("film"), {data: filmData})We’ll adapt it as follows:
var CreateFilm = (filmData) => Do(
ValidateFilmData(filmData),
Create(Collection("film"), {data: filmData})
)ValidateFilmData can now be anything from actual validation such as verifying that a film release date lies in the past, or verifying emails and passwords if we would be creating accounts instead of films. But that doesn’t really make it an explicit schema, so instead we could write that schema down in a json format and can imagine implementing a ValidateSchema function in pure FQL.
var ValidateFilmData = (filmData) => {
var schema = {
title: "string",
language: {
spoken: { name: "string" },
subtitles: { name: "string" }
},
schemaless_thing: "*"
}
return ValidateSchema(schema, filmData)
}In fact, we can improve this even further. In Fauna, everything is a document, including collections. That means we could store this metadata on the collection and make this completely generic. In fact, if you upload a GraphQL schema to Fauna and get the collection, you can actually see the GraphQL schema that Fauna enforces.

We can do the same. Assuming that we have stored a ‘schema’ property on each collection, we could implement this generically by passing in an arbitrary collection and some data.
var ValidateData = (collectionName, filmData) => {
return Let({
collection: Get(Collection(collectionName)),
schema: Select(
["data", "schema"],
Var("collection"),
"any" // a default anything goes schema
)
},
ValidateSchema(schema, filmData))
}When ValidateSchema fails, we could opt to call Abort() which will then cancel the entire transaction. We won't implement the ValidateSchema function here, but do reach out if you would like to see example code, and it might become the next thing we write.
Alternative modelling strategies
We have many modelling options when a document database is seamlessly combined with relational features. In previous chapters, we listed a variety of different implementation strategies for many-to-many relations and implemented the first one:
- Using an association collection that contains the references.
- As an array of references on one side of the relation.
- As an array of references on one both sides of the relation.
- Embedded on one side of the relation
- Embedded on both sides of the relation
The normalized approach was the best default choice, because we didn't know if needed to optimize reads or writes. Now, let’s assume we need to optimize reads over writes, and look into the remaining four approaches for accessing actors and films.
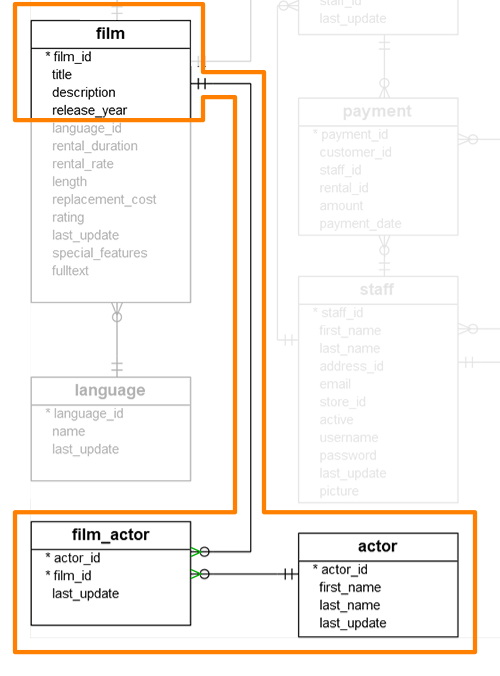
Actors perform in many films, and films have many actors. Although some actors might surprise us,the number of films an actor has played in or the amount of actors listed in a film is typically small. The best part is, once a film is released, these do not change (unless we made a mistake).
Recap: the association collection
Let’s first take a baseline and imagine we model films and actors exactly as we modelled films and categories in the previous chapter. In that case, the query would look as follows:
Map(
Paginate(Documents(Collection("film"))),
Lambda(["ref"],
Let({
film: Get(Var("ref")),
actors: Map(
Paginate(Match(Index("actor_by_film"), Var("ref"))),
Lambda("actorRef", Get(Var("actorRef")))
)
},
// return something
)
)
)The FQL query equals the query plan, which makes it predictable. Therefore, we can easily get a sense of the query performance and can exactly calculate pricing if we know exactly what functions result in reads or writes.
The above query can be analyzed as follows:
- N Gets, where N is the size of the page of films that we retrieve.
- N Index matches, to retrieve a page of related actors.
- N * M invocations of Get to retrieve the actor, where M is the size of the page of actors.
Embedding documents
We can optimize a lot with indexes as we’ll see shortly, but let’s consider embedding first. We can probably assume that the number of actors in a film will remain small, and that we won't need to update it very often. Therefore, we could opt to embed actor data directly in the film.
Create(
Collection("film"),
{
data: {
title: "Academy Dinosaur",
actors: [
{
name: {
first: "Penelope",
last: "Guiness"
}
},
{
name: {
first: "Johnny",
last: "Lollobrigida"
}
},
]
}
}
)What we gain is quite straightforward. A many-to-many query as we wrote in the previous chapter would look as follows:
Map(
Paginate(Documents(Collection("film"))),
Lambda(["ref"], Get(Var("ref")))
) We no longer have to get actors since they are already included in the film document, so it reduces the complexity of our query as follows:
- N Gets, where N is the size of the page of films that we retrieve.
In contrast to the JSONB approach in Postgres, we can still index everything as before and easily add a nested document in a transaction with FQL. For example, we can still easily write an index on actors and retrieve all films where the actor played since Fauna will unroll the array of actors automatically.
CreateIndex({
name: "films_by_actor",
source: Collection("film"),
terms: [
{
field: ["data", "actors", "name", "first"]
},
{
field: ["data", "actors", "name", "last"]
}
]
})What are the trade-offs in this approach?
| Advantages | Disadvantages |
| Efficient both in performance and price. |
|
Although the performance gain might be great, there are clearly a lot of disadvantages to consider. Typically, embedding would be used as a way to speed up frequent queries on data that changes infrequently. In Fauna, it’s a good option when the cardinality of the related data remains small and the embedded entity is either infrequently updated or always updated simultaneously with the parent entity.
Embedding an array of references
The actors field currently contains very little information, but what if we planned to change this in the future? Since embedding would duplicate data, this would require us to update each film where an actor has played and could quickly become unwieldy. Given that requirement, we are better off simply embedding the reference instead of the entire document.
Create(
Collection("film"),
{
data: {
title: "Academy Dinosaur",
actors: [
Ref(Collection("actor"), 288801457207648519),
Ref(Collection("actor"), 288801457207648536)
]
}
}
)In essence, we have eliminated the association document and moved the references directly into the film document. This is something we can do thanks to the excellent support for arrays in Fauna. In contrast to the original query, we can leave out the index match and rely completely on Fauna’s native references.
Map(
Paginate(Documents(Collection("film"))),
Lambda(["ref"],
Let({
film: Get(Var("ref")),
actors: Map(
Select(["data", "actors"], Var("film")),
Lambda("actorRef", Get(Var("actorRef")))
)
},
// return something
)
)
)Since we eliminated the index match, the query now has the following complexity compared to the original query and no longer requires an index.
- N Gets, where N is the size of the page of films that we retrieve.
- N * M invocations of Get to retrieve the actor, where M is the size of the actors array.
This approach sits in between the association collection and the embedded documents. The trade-offs are:
| Positive | Negative |
|
|
Embedding on both sides
We can apply both the embedding or embedding of reference techniques on both side of the relation. Doing this for embedded references probably brings little gain except convenience but does require us to keep both sides of the relations in sync. However, since we can perfectly index arrays there would be little reason to store the references on both sides.
Embedding complete documents on the other hand could make sense if you intend to aggressively optimize reads over writes. An interesting part of the model where that might make sense are rentals and payments.
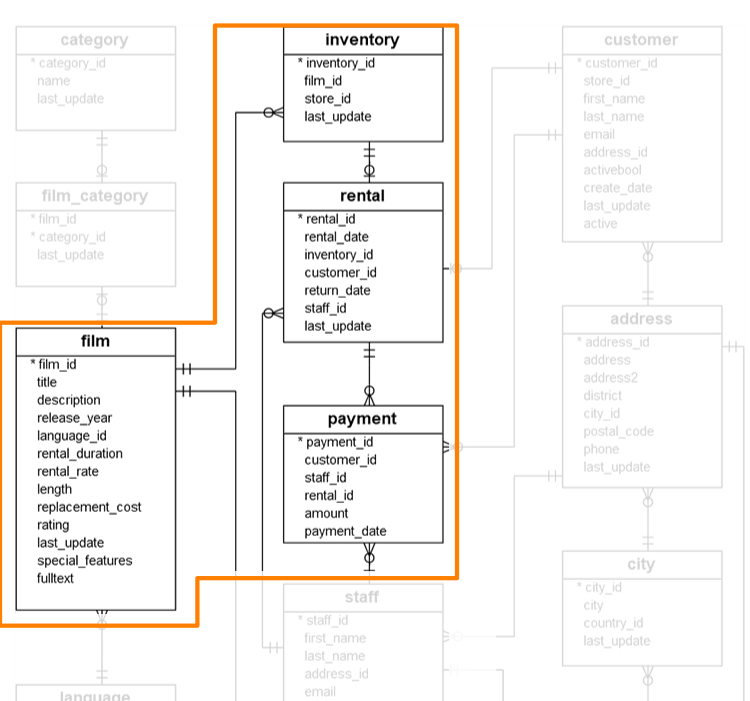
The interesting part is that rentals and payments might become immutable once the film is returned and the rental is paid. At that point we could assume that the inventory will no longer change since a rental does not disappear if a film goes out of a store’s inventory. Imagine that we often query past rentals or payments and want to optimize that access pattern.
We could model these relations completely normalized yet have a closed_rental collection where we store the payment details and inventory film details that we desire to keep directly into the relation. Similarly, we could write the closed rental details immediately in the payments as an embedded_rental property, FQL is procedural which makes it easy to verify whether a certain property (e.g. embedded_rental) is present and revert to following the rental_id if it’s not.
From the data correctness perspective, we’ve seen how FQL allows you to compose queries. We could write a domain specific function that updates the payment document and creates the embedded_rental document in one transaction to ensure our data is correct. The possibilities are endless.
Optimization strategies
Indexes vs Map/Get
Besides of embedding we can also leverage indexes to optimize queries. Fauna indexes are a mix of views and indexes as we know them from Postgres which means indexes do not only accelerate queries but also contain and return data. Until now, our indexes only returned a single reference, but we could also add all values to the document as follows:
CreateIndex({
name: "all_values_films",
source: Collection("film"),
values: [
{ field: ["data", "description"] },
{ field: ["data", "title"] },
{ field: ["data", "language", "spoken"] },
{ field: ["data", "language", "subtitles"] }
]
})Instead of first returning film documents and then retrieving the data, we can now directly get the film data.
Paginate(
Match (Index("all_values_films"))
)The return result is slightly different though, instead of receiving objects, we now receive arrays.
{
data: [
[
"Functional nerd tries to explain functional things",
"Academy Dinosaur",
Ref(Collection("language"), "288878259769180673"),
Ref(Collection("language"), "288878259769180673")
],
[
"Functional nerd tries to explain functional things",
"Academy Dinosaur",
Ref(Collection("language"), "288878259769180673"),
Ref(Collection("language"), "288878259769180673")
]
]
}We can apply this on our many-to-many relationship from the previous chapter. To go from films to category, we used this intermediate index which trades in a film reference for a category reference.
CreateIndex(
{
name: "category_by_film",
source: Collection("film_category"),
terms: [
{
field: ["data", "film_ref"]
}
],
values: [
{
field: ["data", "category_ref"]
}
]
}
)Instead of returning a category reference, we could have immediately included the name as a second value which would have eliminated the last step in the query:
- N Gets, where N is the size of the page of films that we retrieve.
- N Index matches, to retrieve a page of related actors.
Index pages are faster than the Map/Get pattern and depending on the size of your documents, will cut down the required read operations significantly.
Using indexes is a trade-off between writes and reads. Each index will result in an extra write when a document is created or updated, because the index also needs to be updated. Therefore, indexes significantly optimize reads at the cost of a few extra writes.
Huge datasets in a world of pagination
We have seen that pagination is mandatory for enforcing sane limits so that transactions do not take too much time. Although this is a good idea in a scalable database, it might be hard to see how to deal with big transactions or big queries. Let’s take a look at the recommended strategies in case we need to retrieve a lot of data or have to deal with big data migrations.
Retrieving or reasoning over a huge dataset
Although pages can contain up to 100K documents, this is probably too large a page size for many use cases, because you still need time to transfer and process this dataset in your application.
If you do need to retrieve or reason over a very large set, you could paginate through the entire set by launching multiple queries one-by-one from your application. This will return all data that was available at the moment you retrieved your first page. After the last page, you could then use Fauna’s temporality features to check if any new data has arrived.
When it comes to reasoning over a huge dataset, you are probably looking for a database that focuses on analytics (OLAP). At the time of writing, Fauna is primarily an OLTP database and keeps your data safe and correct with strong consistency features, but might not be the best choice for your analytic workloads. However, by using Fauna's temporality features, we can easily stream data to a database or service which excels at analytical or other types of queries such as ClickHouse, Rockset or Snowflake.
In essence, you get the best of both worlds: you can use Fauna as the strongly consistent heart of your data layer, alongside another database that is only eventually consistent, but optimized for analytical workloads.
Dealing with big data migrations
In many cases, we might be tempted to write big transactions. For example, let's say we made a mistake in our document format and want to write a data migration which traverses all documents and transforms them to the new format. This is perfectly possible in a traditional database such as Postgres, but there is a caveat since it could result in a database lock and severe production problems.
And it's specifically to avoid these kinds of problems that such a “big bang” migration goes against the philosophy of a multi-tenant scalable database. Instead, just like with querying, transforming many documents would require you to paginate through them and complete such a migration in multiple steps. Fauna’s approach to pagination takes this recommended practice to process data migrations asynchronously in smaller “trickles”.
Of course, by the time you have processed all pages, new data might have arrived. In contrast to databases like Postgres that do not support temporality, Fauna makes it much cleaner to develop such asynchronous migration strategies since you can ask Fauna whether any new data was created between the start of the migration and the last migration step. This allows for improvements on the typical approach towards zero downtime migrations.
However, there are better ways to deal with data migrations; let’s look at a theoretical approach.
Low and zero downtime data migrations
Data migrations are an interesting problem in any database that contains a reasonable amount of data. However, in many cases, we can avoid big data migrations by employing more advanced techniques as explained in this article.
Step 1. Change your schema in an ‘add-only’ fashion.
Step 2. Perform the data migration in small batches.
Step 3. Once done, briefly take the application down for a final run.
Step 4. Clean up the old schema properties. In Fauna, thanks to the temporal aspect, we can actually do more and achieve zero downtime. Fauna is schemaless, so instead of cleaning up old schemas, we simply update our UDFs, resulting in the following approach.
Step 1. Change your queries (that live inside UDFs).
Step 2. Perform the data migration in small batches.
Step 3. Use temporality to run migrations on new data and __add magic.__Such magic could be done in an If() test at the end of your batch, which verifies whether your batch size is zero (or at least very small), and then transactionally updates the UDFs to their new format once the batch is done. Being able to express such statements transactionally allows us to have zero downtime.
That’s only one of the approaches. For complex data migrations, we could also adapt our queries to be able to deal with both formats depending on the timestamp and update the format whenever we write to the document. This is something you would typically do in the application code, but since FQL is easily composable, we can do it in a safer and saner way. Remember our query to retrieve languages in the previous article.
var GetLangFromFilm = (film, langType) => Get(
Select(['data', 'language', langType], Var("film"))
)Imagine that we had started with one type of language. Our query would have looked as follows:
var GetLangFromFilmV1 = (film) => Get(
Select(['data', 'language'], Var("film"))
)We could then change the query and take full advantage of FQL to compose the query out of two versions, either dependent on the timestamp or dependent on whether a specific property is present. The new query could look as follows:
var GetLangFromFilmV1 = (film) => Get(
Select(['data', 'language'], Var("film"))
)
var GetLangFromFilmV2 = (film, langType) => Get(
Select(['data', 'language', langType], Var("film"))
)
var GetLangFromFilm = (film, langType) => If(
GE(Select(['ts'], film), "< some timestamp >"),
GetLangFromFilmV1(film, langType),
GetLangFromFilmV2(film, langType)
)Although it’s not feasible for all types of queries, it’s definitely an approach to consider in combination with the previously mentioned approach.
Conclusion
Some of the possibilities we hint at are very exciting, but would require a separate article with code samples to fully explore. Currently, we describe these approaches with code samples, but don’t zoom in to the finer details yet. Let us know whether one of these techniques piques your interest, and the next article, we write might zoom in on one of these approaches with a complete sample program.
If you enjoyed our blog, and want to work on systems and challenges related to globally distributed systems, serverless databases, GraphQL, and Jamstack, Fauna is hiring!
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.