


Shrink your dApp's server footprint with Fauna
Zee Khoo|May 13th, 2022
Kitty Items
Kitty Items is a full-stack dApp (decentralized application) sample provided by Dapper, the makers of NBA Top Shot and CryptoKitties. It serves to provide developers a reference to implementing the deployment of contracts, minting of NFTs, and integrating with user wallets. As a decentralized app, it is built with Flow’s Cadence smart contract programming language. However, to fully implement a complete NFT marketplace, there are off-chain data requirements that need to be met, which is why the project includes a back end, shown in the diagram below.
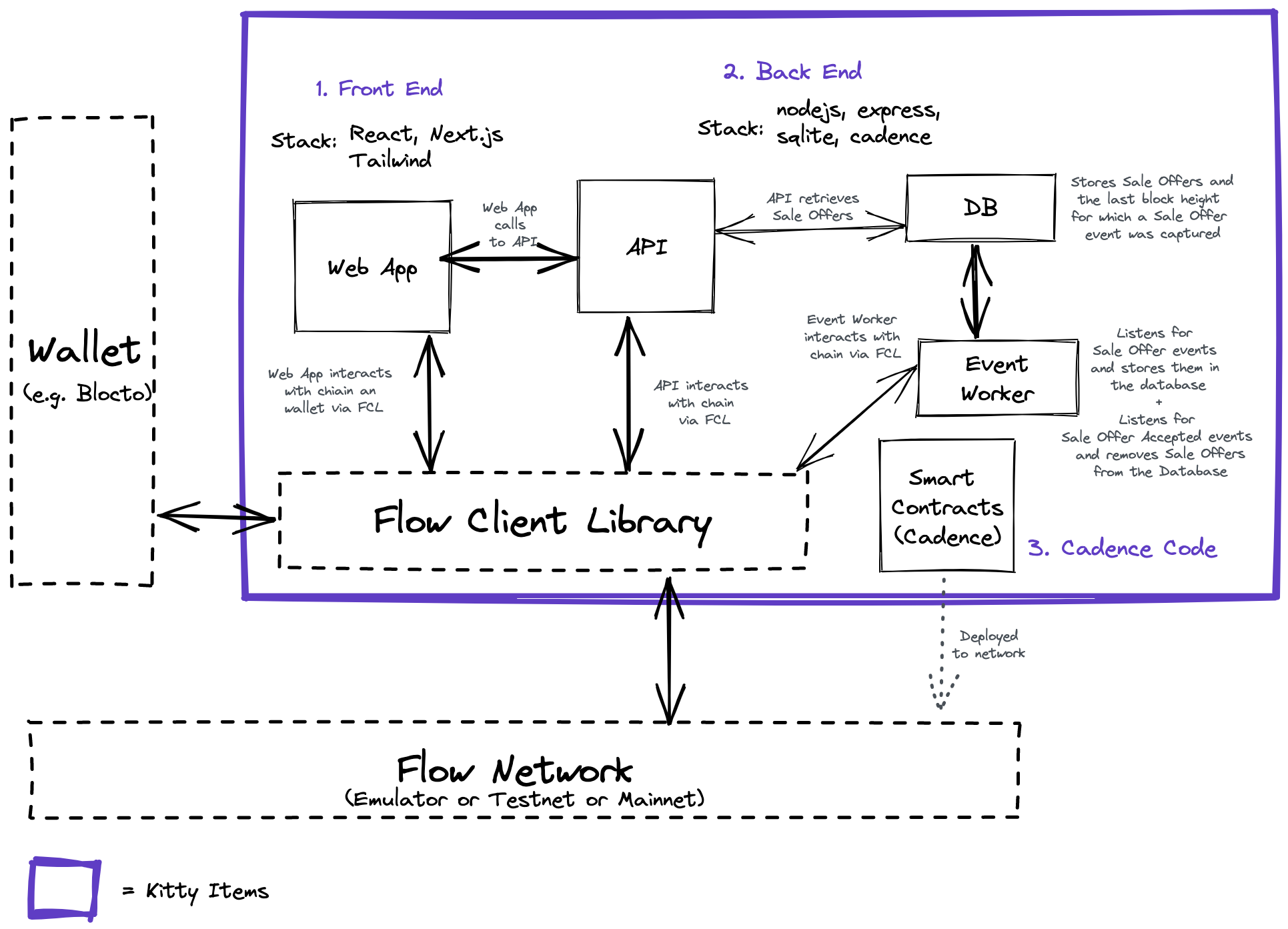
A critical component of the back end is the Event Worker, whose role is to poll events from the Flow blockchain. Polling is a common pattern used by dApps to aggregate blockchain events in real time, and in the case of Kitty Items, we’re listening for Sale Offer events. When items are offered for sale on Flow, the corresponding “listing item” entry is inserted into the Listing table in the database (storing its price, rarity, kind/type, owner, etc.), so that it can be easily queried by the Web Application.
Kitty Items provides a sample implementation using a relational database (SQLite3). In addition to the Listing table (described above), there’s a BlockCursor table. The Event Worker reads a range of blocks from the Flow network and processes them sequentially. When processing is done, it records the last block processed, as it needs that value as the starting block for the next polling iteration. This continues in perpetuity.
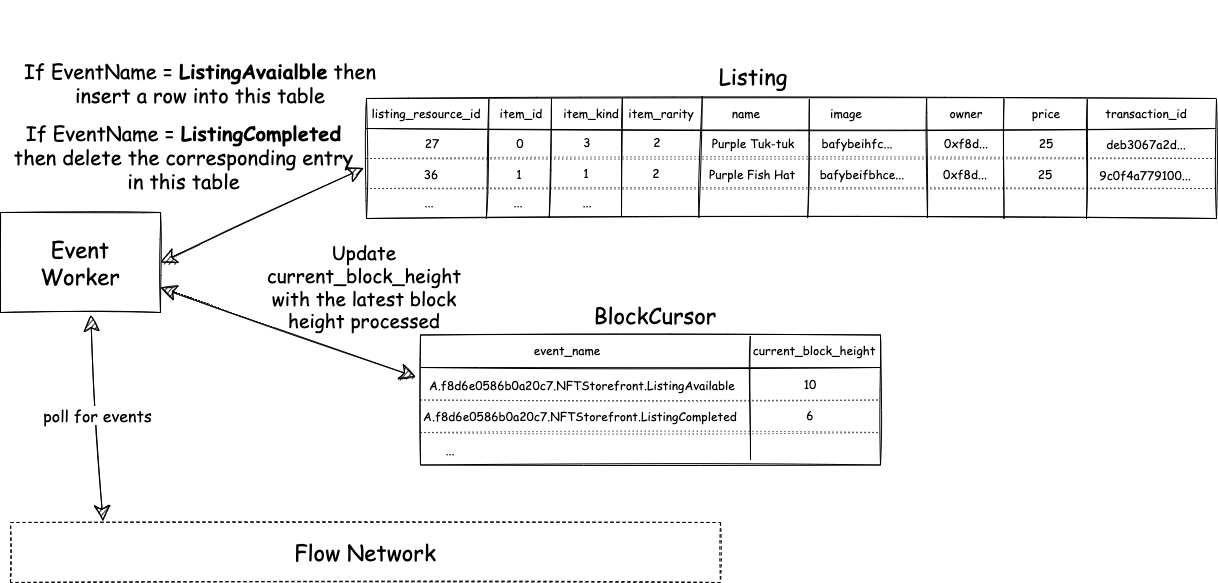
What we’re building
As simple as the database schema may be, deploying and maintaining a database is still overhead which can be avoided if we chose a serverless route. Fauna is a globally distributed and serverless database that guarantees transactional consistency. In this tutorial, you’ll learn how to use Fauna as a serverless alternative to the relational database in the Kitty Items sample app.
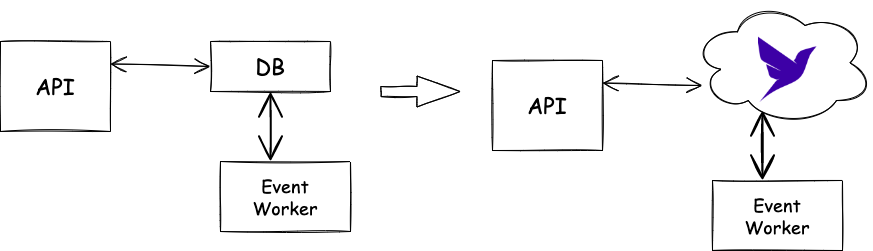
Setting up Fauna
To follow along with this post you must have access to a Fauna account. You can register for a free Fauna account and benefit from Fauna’s free tier while you learn and build, and you won’t need to provide payment information until you are ready to upgrade.
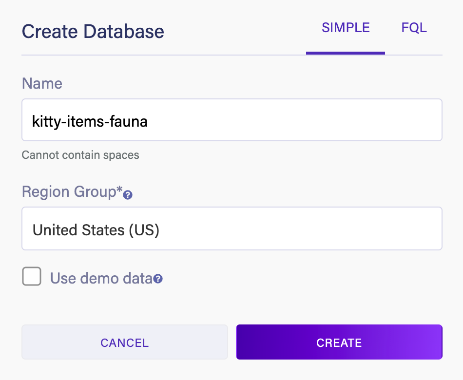
Login to the dashboard and create a new database. Provide a name (e.g. kitty-items-fauna) and pick a Region Group (e.g. United States (US)), then click CREATE:
Using the left-navigator, select Security. And under the KEYS tab, click NEW KEY.
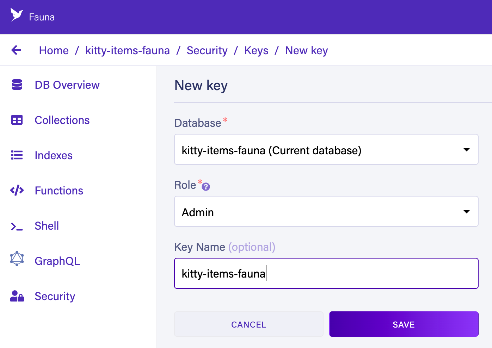
The Database and Role fields are pre-populated. For this tutorial, we’ll leave the defaults as is, but know that you can provide granular security controls through extra configuration.
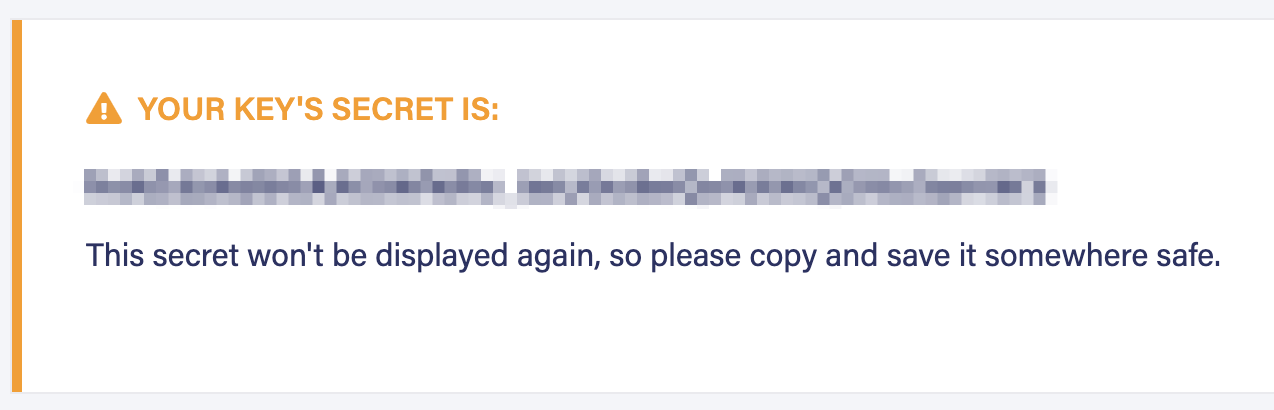
Provide a Key Name (optional) and SAVE. In the next screen, copy the secret value for the next step (you will not be able to see this value again in the dashboard).
Kitty Items project setup and installing the Fauna javascript driver
Head over to the project README and follow along to install the project dependencies and clone the project. Then install packages:
- Run
npm installin the root of the project.
Next, we perform our modifications to the project: Install the Fauna javascript driver in the
api/ folder:cd api/ && npm install --save faunadbBack at the root of the project, locate the
.env.emulator file and add the following environment variables:FAUNADB_KEY=<<the key you retrieved from the prior step>>
FAUNADB_DOMAIN=db.fauna.comForFAUNADB_DOMAIN, if you created your database in:
db.us.fauna.comdb.eu.fauna.comuse db.fauna.comVisit the Region Groups documentation to learn more about how Fauna addresses data locality use-cases.
At the top of the
/api/src/services/block-cursor.ts class file, import faunadb and instantiate the fauna client:import faunadb from "faunadb";
const {Call, Function} = faunadb.query;
const FAUNADB_KEY = process.env.FAUNADB_KEY!;
const FAUNADB_DOMAIN = process.env.FAUNADB_DOMAIN;
const client = new faunadb.Client({
secret: FAUNADB_KEY,
domain: FAUNADB_DOMAIN
});Repeat the above for
/api/src/services/storefront.ts.Inspect the contents of both files. In there you’ll find methods (two for the BlockCursorService class, and four for the StorefrontService class) that interact with the database. In their original form, these methods use ORM to interact with a SQL database. Our goal will be to replace the ORM interaction with an API call to Fauna. To do this, you’ll write some user-defined functions (UDF): one UDF per method that is being replaced, to be more precise.
User-defined functions
Fauna enables users to create user-defined functions (UDFs), which are similar to stored procedures found in other databases. Essentially, this allows business logic to be abstracted from the application layer and embedded in the database. Once defined, functions can be called directly from applications. This enables Fauna to be a solution that manages data, schema, and logic in a single solution. This key feature is what’s going to allow you to easily replace the SQL database in Kitty Items with Fauna.
1. Create collections
Head back to your Fauna dashboard. From the left-navigator, select Collections and create two collections with the names BlockCursor and Listing. These 2 collections directly replace the like-named tables in the SQL database:
- BlockCursor keeps track of the latest block processed in the blockchain.
- Listing store marketplace items for sale.
2. Create the indexes
Use the left navigation and select Shell. Then run the following queries to create a few indexes:
The first index is for querying BlockCursors by its eventName and also imposes a unique constraint on it:
CreateIndex({
name: "block_cursor_by_event_name",
unique: true,
source: Collection("BlockCursor"),
terms: [
{ field: ["data", "eventName"] }
]
})This next index is for querying Listing by its id and imposes a unique constraint on it:
CreateIndex({
name: "listings_by_item_id",
unique: true,
source: Collection("Listing"),
terms: [
{ field: ["data", "item_id"] }
]
})Finally, the index below is to list Listings ordered by their last updated timestamp (
ts):CreateIndex({
name: "listings_ordered_by_ts_desc",
source: Collection("Listing"),
values: [
{ field: ["ts"], reverse: true },
{ field: ["ref"] }
]
})3. Define functions
With the Collections and Indexes defined, you’re ready to define UDFs and refactor the methods by calling these UDFs.
First up is the findOrCreateLatestBlockCursor method in the BlockCursorService class. Execute the query below in the Fauna dashboard Shell.
UDFs are written in Fauna’s native query language, which allows you to programmatically operate over collections and indexes. The expressiveness of the language allows us to reproduce the findOrCreateLatestBlockCursor method’s original implementation.
CreateFunction({
name: "findOrCreateLatestBlockCursor",
body: Query(
Lambda(
["latestBlockHeight", "eventName"],
Let(
{
match: Match(
Index("block_cursor_by_event_name"),
Var("eventName")
),
count: Count(Var("match")),
blockCursor: If(
GT(Var("count"), 0),
Get(Var("match")),
Create(Collection("BlockCursor"), {
data: {
eventName: Var("eventName"),
currentBlockHeight: Var("latestBlockHeight")
}
})
)
},
Merge(
{ id: Select(["ref", "id"], Var("blockCursor")) },
Select(["data"], Var("blockCursor"))
)
)
)
)
})After creating the above UDF, return to
/api/src/services/block-cursor.ts and replace the method findOrCreateLatestBlockCursor with the following, which is a simple call to the UDF defined above:async findOrCreateLatestBlockCursor(
latestBlockHeight: number,
eventName: string
) {
const res = await client.query(
Call(Function('findOrCreateLatestBlockCursor'),
latestBlockHeight, eventName)
);
return res as BlockCursor;
}Notice – as we previously alluded to – a single call to the UDF replaces everything that the original code did.
Next, repeat the same process for updateBlockCursorById. Back in the Fauna dashboard, run the following query in the Shell:
CreateFunction({
name: "updateBlockCursorById",
body: Query(
Lambda(
["id", "currentBlockHeight"],
Let(
{
ref: Ref(Collection("BlockCursor"), Var("id")),
blockCursor: Get(Var("ref")),
cursorCurrentHeight: Select(
["data", "currentBlockHeight"],
Var("blockCursor")
),
result: If(
Equals(
Var("cursorCurrentHeight"),
Var("currentBlockHeight")
),
Var("blockCursor"),
Update(Var("ref"), {
data: {
currentBlockHeight: Var("currentBlockHeight")
}
})
)
},
Merge(
{ id: Select(["id"], Var("ref")) },
Select(["data"], Var("result"))
)
)
)
)
})Likewise, in
/api/src/services/block-cursor.ts, replace the code in updateBlockCursorById with a call to the above UDF:async updateBlockCursorById(id: string, currentBlockHeight: number) {
const res = await client.query(
Call(Function('updateBlockCursorById'), id, currentBlockHeight)
);
return res as BlockCursor;
}Repeat the process for four methods in StorefrontService class:
- Create the addListing UDF in Fauna:
CreateFunction({
name: "addListing",
body: Query(
Lambda(
[
"listing_resource_id",
"item_id",
"item_kind",
"item_rarity",
"name",
"image",
"owner",
"price",
"transaction_id"
],
Let(
{
listingRef: Ref(
Collection("Listing"),
Var("listing_resource_id")
)
},
Do(
If(
Exists(Var("listingRef")),
"do nothing",
Create(Var("listingRef"), {
data: {
listing_resource_id: ToNumber(
Var("listing_resource_id")
),
item_id: ToNumber(Var("item_id")),
item_kind: ToNumber(Var("item_kind")),
item_rarity: ToNumber(Var("item_rarity")),
name: Var("name"),
image: Var("image"),
owner: Var("owner"),
price: ToNumber(Var("price")),
transaction_id: Var("transaction_id")
}
})
),
Var("listing_resource_id")
)
)
)
)
})Update the method having the same name in
/api/src/services/storefront.tsaddListing = async (listingEvent) => {
const owner = listingEvent.data.storefrontAddress
const listingResourceID = listingEvent.data.listingResourceID
const item = await this.getListingItem(owner, listingResourceID)
try {
await client.query(
Call(Function('addListing'),
listingResourceID,
item.itemID,
item.kind.rawValue,
item.rarity.rawValue,
item.name,
item.image,
owner,
item.price,
listingEvent.transactionId
)
);
} catch(e) {
console.log(e);
console.log(listingEvent);
}
}- Create the removeListing UDF:
CreateFunction({
name: "removeListing",
body: Query(
Lambda(
"listingId",
Let(
{ ref: Ref(Collection("Listing"), Var("listingId")) },
If(
Exists(Var("ref")),
Do(
Delete(Var("ref")),
"Deleted"
),
"Not found"
)
)
)
)
})Update the method having the same name in
/api/src/services/storefront.ts.removeListing = async (listingEvent) => {
const listingResourceID = listingEvent.data.listingResourceID
await client.query(
Call(Function('removeListing'), listingResourceID)
)
}- Create the findListing UDF:
CreateFunction({
name: "findListing",
body: Query(
Lambda(
"itemId",
Let(
{
match: Match(
Index("listings_by_item_id"),
ToInteger(Var("itemId"))
),
count: Count(Var("match"))
},
If(
GT(Var("count"), 0),
[Select(["data"], Get(Var("match")))],
[]
)
)
)
)
})Update the method having the same name in
/api/src/services/storefront.ts.findListing = async (itemID) => {
const res = await client.query(
Call(Function('findListing'), itemID)
)
return res as Listing;
}- Create the findMostRecentSales UDF:
CreateFunction({
name: "findMostRecentSales",
body: Query(
Lambda(
["pageSize", "params", "minterAddress"],
Let(
{
alldata: Select(
["data"],
Map(
Paginate(
Match(Index("listings_ordered_by_ts_desc")),
{ size: Var("pageSize") }
),
Lambda(
"listing",
Select(
["data"],
Get(Select([1], Var("listing")))
)
)
)
)
},
Filter(
Var("alldata"),
Lambda(
"item",
And(
If(
ContainsField("owner", Var("params")),
Equals(
Select(["owner"], Var("params")),
Select(["owner"], Var("item"))
),
true
),
If(
ContainsField("kind", Var("params")),
Equals(
ToNumber(Select(["kind"], Var("params"))),
Select(["item_kind"], Var("item"))
),
true
),
If(
ContainsField("rarity", Var("params")),
Equals(
ToNumber(Select(["rarity"], Var("params"))),
Select(["item_rarity"], Var("item"))
),
true
),
If(
ContainsField("minPrice", Var("params")),
GTE(
Select(["price"], Var("item")),
Select(["minPrice"], Var("params"))
),
true
),
If(
ContainsField("maxPrice", Var("params")),
LTE(
Select(["price"], Var("item")),
Select(["maxPrice"], Var("params"))
),
true
),
If(
And(
ContainsField("marketplace", Var("params")),
Equals(
Select(["marketplace"], Var("params")),
"true"
)
),
Not(
Equals(
Select(["owner"], Var("item")),
Var("minterAddress")
)
),
true
)
)
)
)
)
)
)
})Update the method having the same name in
/api/src/services/storefront.ts.findMostRecentSales = async (params) => {
const res = await client.query(
Call(Function('findMostRecentSales'), 100, params, this.minterAddress)
);
return res as Listing;
}And that’s it! Follow the “local development” README to run the project locally:
Note that for the sake of brevity, we’ve left out the steps refactoring out the relational database (which now does nothing), but it should be a worthwhile exercise to complete on your own.
Check your Fauna dashboard and notice that two documents have been created in the BlockCursor collection. This should confirm that the app is successfully connecting to the database!
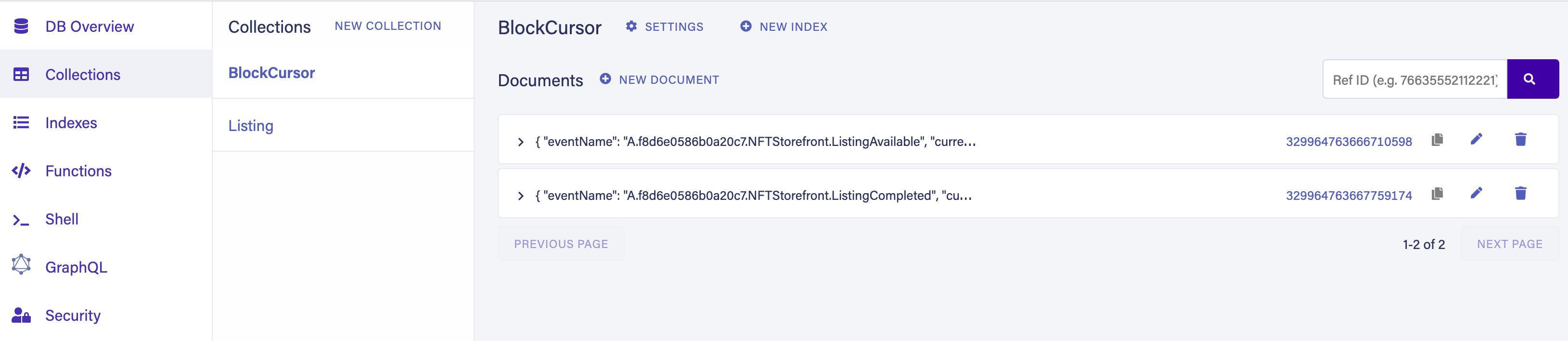
Now visit
http://localhost:3001, login and play around with the sample app. As you mint items, list for sale, and remove them, you should see the Listing collection get updated: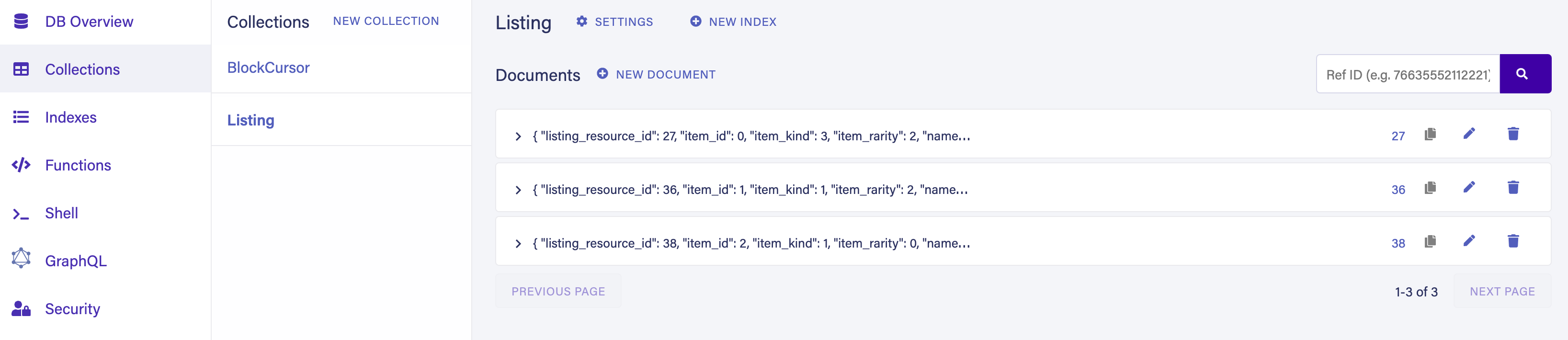
Next steps
The convenience and flexibility of Fauna UDFs allows us to easily refactor an existing project’s database implementation. With this we’ve also advanced our architecture one step closer to being fully serverless. We could take things a step further by moving the api endpoints to Lambda/Cloud Functions or to Edge Computing environments. But for now we’ll save that as a topic for perhaps a future post.
A “no servers required” database like Fauna aligns well with dApp development. Besides providing a no-ops environment that scales with your workload, Fauna’s globally distributed footprint provides consistent and low latency to your users, no matter where they reside. This is all the while being ACID, with flexible indexing capabilities and a highly expressive query language – so you can focus on the business logic of your apps instead of engineering around eventual-consistency, duplicating data or locking in your schema without encountering problems modifying it down the line.
If you enjoyed our blog, and want to work on systems and challenges related to globally distributed systems, serverless databases, GraphQL, and Jamstack, Fauna is hiring!
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.