

Data Security in the Age of Serverless Apps
Cloud native deployments without cloud-native technology can increase the chances of unexpected access to services and data. In 2017, 26,000 unsecured MongoDB instances were deleted in addition to other high-profile breaches. A cloud native database can’t encourage insecure practices in development and then expect production deployments to follow best practices. That’s why every connection to Fauna uses a key secret corresponding to a particular level of access, and why Fauna makes it easy to model application security in the database. This article will show you why modeling security in the database is good for more than just defense-in-depth, when your database understands your data you get additional security and flexibility.
Fauna’s security model is applied to every query in the API.
With GDPR coming into effect, now is a good time to think about data security. Fauna offers several security APIs that can support your privacy initiatives. What you can learn from this article:
- How Fauna features like access keys, tokens, delegation, and data expiry can be used to ensure privacy.
- How common application scenarios like multi-tenant SaaS hosting, social content publishing, and collaborative workgroups can model security in the database.
- How database security features can support GDPR principles.
Fauna Security API
Fauna’s security model is applied to every query in the API. Each client is instantiated with a connection secret, which corresponds to an access key. Access keys can either have database level access, or object level access. Administrative keys are not used for data operations, a default choice designed to limit proliferation of dangerous keys.
Database Access Keys
Database keys can be one of a few levels: admin, server, server-readonly, and client. These apply to a database and for admin keys, to the ability to manage sub-databases in the multi-tenant tree.
Admin keys are used to create databases, and set priority levels. An admin key in a particular database can create sub-databases in that database, provision access keys for sub-databases, and update the priority and other settings for each sub-database. Priority is inherited from parent databases. More about administering the database hierarchical multi-tenancy tree in this article.
When you use the dashboard or another tool to create a database in Fauna, the connection uses an admin key. Simple apps will only require one database, but most Fauna deployments will use hierarchy to define resource and access sharing. Admin keys lay out production, staging, and development environments, and can be used at runtime for applications which self-provision databases (for new customer signup, for instance).
Server keys are used when you want to work inside a database. Use an admin key (or the dashboard) to create a server key for the database you want to store data in. Server keys are the ones you’ll end up pasting into your code following best practices to deliver to your application runtime. Server keys can write to any class and bypass access control rules, so in applications where you are using object-level access control (discussed below) you’ll primarily use server keys for schema manipulations and administrative queries. In applications where the data is all part of the same security context, your application might do all its work with server keys. This is probably the majority of applications, because let’s face it: no matter how easy the API is, many applications that could benefit from object level security at the database layer never get around to modeling it. Hopefully, this post shows you enough of the benefits of deeper security modeling, especially around GDPR and similar constraints, that you consider applying these lessons in your app.
Many applications that could benefit from object level security at the database layer never get around to modeling it.
Readonly keys are a kind of server key which cannot modify data. This is nice because it’s less dangerous to run queries which skip the access control policy if you know they are read only. These are the keys I’d give to a more-privileged process that doesn’t need to write, but needs to do arbitrary reads. I’d still suggest writing through a token-based connection to take advantage of ACL features, as some constraints are imposed for correctness reasons, and being forced to write through a user-defined function or other defined interface can be less risky to the organization.
Client keys can only access objects which have declared “public” in their ACL. So for instance to allow for anonymous self-service provisioning of new users through a Fauna client connection, you can create a user class and mark it’s creation permission as “public.” Then provision a Fauna client key and paste it in your code. If you use an index to find which object to login as, you’ll need to mark that index as “public” too. Visitors can issue queries to create new users, and to look themselves up by login token and test credentials. More about that in the next section.
Object Access Control
When you decide to model security at the application layer, a lot of your work takes place at the object level. Constructions like single user data repositories, social activity feeds, and collaborative workspaces are all built on simple Fauna primitives like access control lists, authentication tokens, access delegation, and document expiry.
This is done by tagging documents with access control lists (ACLs) that correspond to who can do what kind of operations on the document. Fauna’s API is flexible enough to express role-based access control (RBAC) and other access control patterns in terms of object ACLs and the objects they list.
A database connection can be established on behalf of any document that has credentials, by provisioning a token for those credentials and using the token as a connection string. The connection established using this token will have access to the any documents which list the credentialed document in the ACL.
Listing every user and process that has access to a document as an individual entry in the ACL can get cumbersome, and granting access to every member of a class limits flexibility. Access delegation allows objects to grant their access capabilities to other objects. So for instance, all real estate listings could list the agent-team document as a writer in their ACL. The agent-team document lists all the members of the team as delegates, so they can modify listings without being directly included in the listing ACL. That way, if team membership changes, you only have to change the agent-team document, not every single document with an ACL. It also means users can have more than one reason they can apply a certain operation, so security roles are composable.
Designing for privacy at all levels prevents data from accidentally being used for purposes other than that for which consent was given.
Fauna’s time-to-live document expiry (TTL) feature can automatically remove old data. An app built around a 24-hour lifetime for social content could easily and automatically tag all content to expire after a day. GDPR’s principle of data minimization suggests TTLs should be applied to most intermediate data created by data processors, so that data artifacts created as part of generating recommendations or other processing are automatically deleted once their purpose has been served. Designing for privacy at all levels prevents data from accidentally being used for purposes other than that for which consent was given. By deleting data automatically, the chances of unwittingly violating GDPR are reduced.
Modeling Application Security
Fauna’s security focus encompasses a wide variety of modern application paradigms. In the following sections, we’ll talk about three patterns that encompass a wide swath of the application types that exist today. These patterns are multi-tenant SaaS hosting, social content publishing, and collaborative workgroups. When applications model security constraints in the database using Fauna, GDPR principles like data minimisation, the right to access and the right to erasure can be supported with features like automatic data expiry, authentication, authorization, and access delegation.
When applications model security constraints in the database using Fauna, GDPR principles like data minimisation, the right to access and the right to erasure can be supported with features like automatic data expiry, authentication, authorization, and access delegation.
SaaS Data Repository
If your service is offered in the cloud as a stand-alone customer experience, for instance in applications like vertical-specific enterprise SaaS, individual user storage and sync, or self-contained game worlds, the SaaS data repository layout is for you. Fauna multi-tenancy means a single cluster can support an arbitrarily complex tree of databases, inheriting access control and QoS prioritization.
In database management systems without support for multi-tenancy, the complexity of maintaining a database per tenant can overwhelm the benefits. In my experience discovering customer requirements at Couchbase, we saw a hunger for simpler multi-tenant management and resource control, especially when data sharing requirements are more complex for instance in telecom or banking use cases that wanted to create a database per account. Fauna’s hierarchical approach makes it easier to manage quality-of-service (QoS) for a large fleet of databases, and support a mixture of popular and less used databases. Read about the patterns that can be achieved with Fauna’s hierarchical multi-tenancy.
Keeping user and customer data in isolated databases is aligned with GDPR principles, because it is easy to manage a single customer’s database as a unit, and harder to run queries aggregating user behavior from users who don’t opt-in. Databases can be deleted or copied, granting right of erasure and access. A database-per-customer design is also congruent with the principles of consent and data minimisation, as access for processors can be granted and revoked for the entire data set, and old customer accounts, inactive game worlds, or unused individual storage areas can be deleted. In addition to deletion and access control, Fauna is working on a locality control feature to allow replication topology to be configured per-database, so you can manage a single cluster, but keep each customer’s data inside its jurisdiction.
This multi-tenancy pattern is concerned with databases, Fauna’s container for data. If your customer application is multi-user, like retail, hospitality, or compliance, the object level patterns in the rest of the article will also apply. They are more fine grained than the data container, and can model most shared and collaborative data flows, within an individual database.
Social Publishing
In a social publishing app, users can post content and follow other users. The main screen of the app is the recent content from everyone the user follows. In this model, objects can be created and read by anyone in the user class, but only updated by their original author. Additionally, users can grant and revoke permissions for the application to run certain kinds of processing on their data, depending on which application feature-sets the user engages in. Querying a model like this is discussed in our post about how Fauna unifies document, relational, graph, and temporal data models.
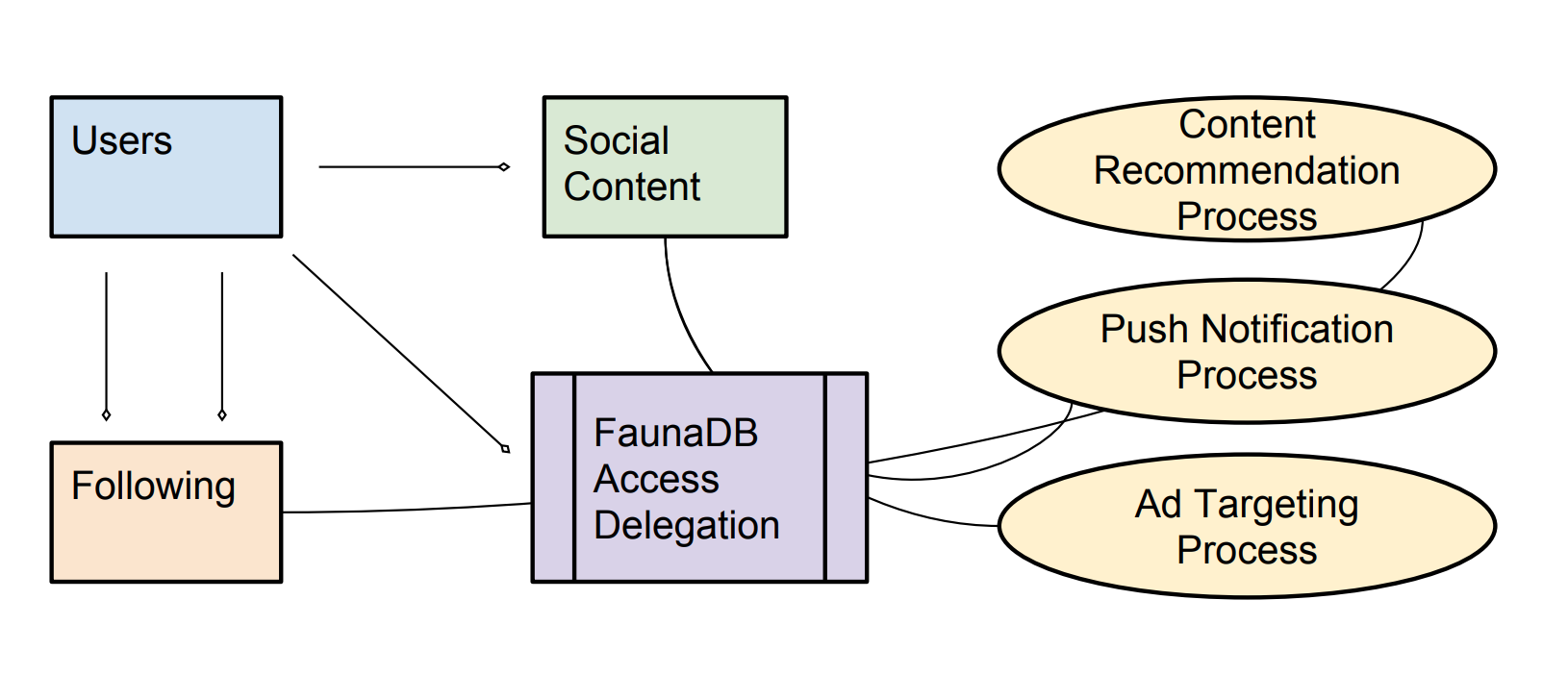
GDPR’s principle of data minimisation requires applications to collect only the data they need, and use it only for the purpose for which consent was given. In our application, various kinds of processing can be run on user content, but only if the user opts in. So for instance, without consent for processing, users would not receive content recommendations. Additionally, the push notification process can only access the data of users who opt in, and similarly users who have not consented to ad targeting will only see un-targeted ads.
Users manage processing permissions by delegating access to their content via Fauna APIs.
This is implemented in Fauna with the following access control rules:
- Connections to the database can be authenticated as a user instance or as a processing agent.
- User instances can read and author social content, and update content for which they are the author. User instances can create and delete following relationships where they are the follower.
- Processing agents can only read social content or following relationships for users that have opted-in to the particular feature the process supports. Users manage processing permissions by delegating access to their content via Fauna APIs.
- Data stored by the processing agent in conjunction with a particular feature can only be read using the key corresponding to the user’s consent. If consent is revoked, the key is removed and access is no longer possible, even before data deletion takes place.
This pattern is also aligned with the GDPR’s right of erasure and right of access. By accessing the database via a user and their delegates, you can get an accurate snapshot of all the data stored for a particular user, for download or deletion.
By accessing the database via a user and their delegates, you can get an accurate snapshot of all the data stored for a particular user, for download or deletion.
In a production app, you might extend this model by decomposing the user’s access into capabilities, with a document per capability. So the user would have a document for messaging, one for photos, etc. As well as keys corresponding to access which are granted to particular processes belonging to the features which the user opted into. If the user later opts of of ad-targeting, push notifications, or content recommendation, the key is simply thrown away, and the data accessed and stored by those processes is no longer accessible.
Collaborative Workgroups
Collaborative workgroup patterns show up in all sorts of applications. Everything from shared document editing, to electronic medical records, to inventory tracking and retail point-of-sale shares a basic model where groups are defined and can share access to collaborative data. The important aspect of this model is defining a group, and then deciding which users are members of it, and which objects belong to the group.
In the real estate listing example discussed at the beginning of the article, the group is the agent-team, the users are the agents, and the app objects are listings data, documents, onsite comments, photos, etc.
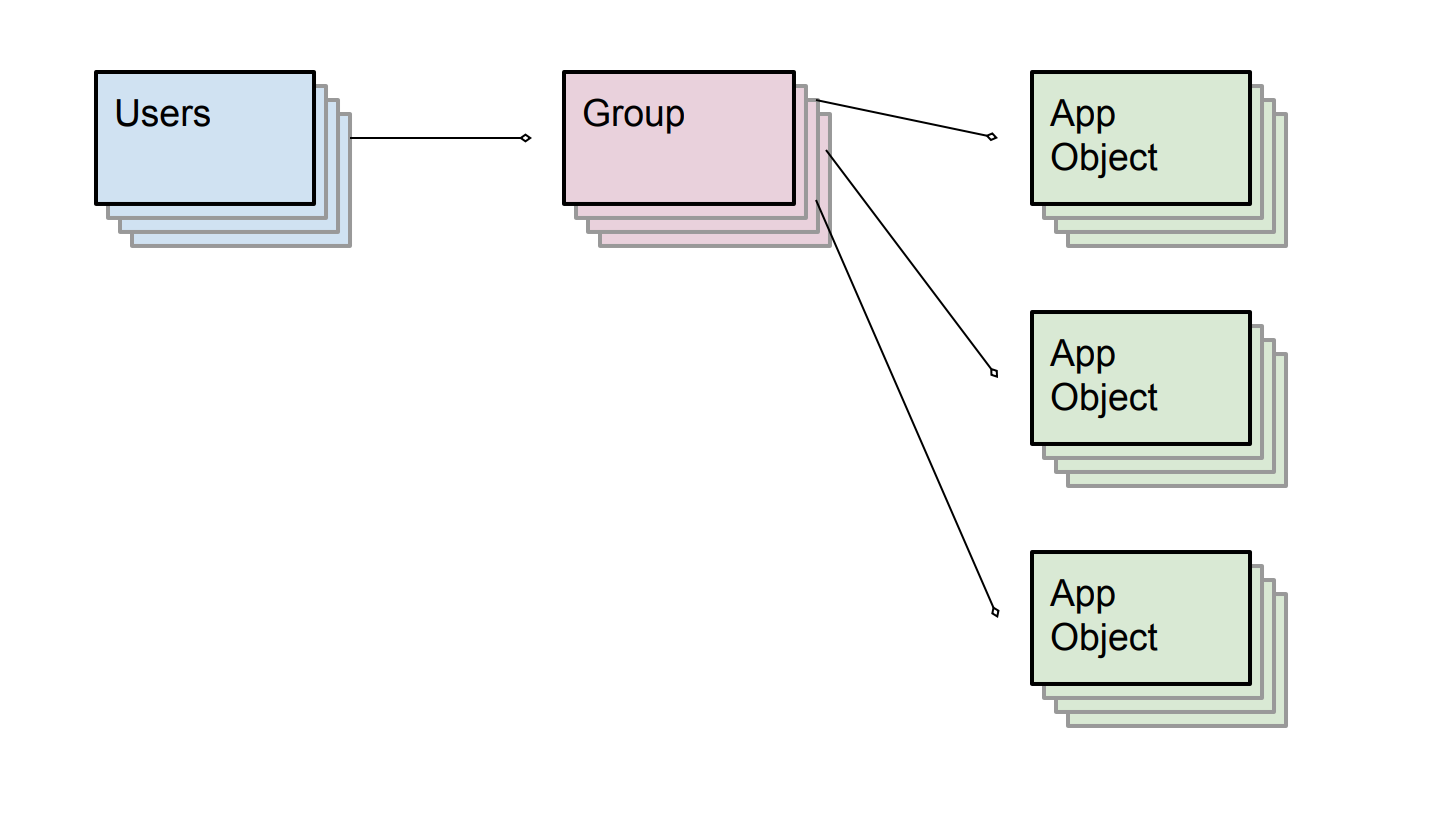
In Fauna the model above would be represented by tagging the app objects on the way in, with ACL entries granting the correct group(s) access to read, write and modify the objects themselves. By writing authorship and ownership information into your objects you can better track how data flows in your system.
Fauna’s temporal retention allows changes in data to be tracked over time.
One of the biggest challenges with the GDPR for collaborative workgroup software is the potential for collaborators to introduce personal data without proper safeguards. Knowing which collaborators had access to which application objects at which time can be crucial for containing breaches and mitigating leaks. Fauna’s temporal retention allows changes in data to be tracked over time. In this model you can query group membership and session status, for tracking and audit purposes.
Conclusion
Security and privacy go beyond the features offered by a database, and extend into how inviting it is to build programs that are aligned with principles like the GDPR. This article shows how common application scenarios, when built with Fauna’s security primitives, can be extended in alignment with GDPR principles. I hope that by showing this additional benefit to deep modeling of application security in the database, you are further convinced that it’s worth doing.
If you are interested in another benefit of modeling application rules in the database, take a look at this talk from ServerlessConf Austin about how I built the object security model for a multi-user TodoMVC clone. The benefit here is that AWS Lambda functions can be supplied a Fauna access token by AWS API Gateway proxied requests, so your code connects to the database as the user who is using the app. Jump to 11 minutes in if you want to skip the Fauna pitch.
If you enjoyed our blog, and want to work on systems and challenges related to globally distributed systems, serverless databases, GraphQL, and Jamstack, Fauna is hiring!
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.