


Modernizing from PostgreSQL to Serverless with Fauna Part 1
Brecht De Rooms|Feb 22nd, 2021
Introduction
PostgreSQL (AKA Postgres) is one of the finest relational database management systems ever created. However, the Postgres we know and love is a client-server database that requires operational setup and maintenance to keep your instance or cluster available at all times, and does not scale easily to the modern Internet.
Fauna is a distributed serverless data API that follows the document model, offers complete data consistency, and supports a functional query language familiar to modern software developers. Teams using Fauna are freed from burdensome operations and can achieve higher productivity levels without compromising on robust database functionality.
Developers who are concerned about scale, distribution, and operational efficiency can benefit a lot from modernizing from Postgres to serverless. In this article, we help you understand the transition by transforming a sample Postgres data model to Fauna and elaborating on the trade-offs.
Objectives
- Learn about the key differences between Fauna and Postgres
- Understand how to translate Postgres concepts into Fauna concepts
- Get some hands-on coding and a repository to easily set up the example Fauna model
- Show how we can build our own Domain Specific Language with FQL
- Hint at architectures/approaches to optimize queries, compose queries, or achieve zero downtime migrations
How different is Fauna from Postgres?
Before we dive in, it’s important that we first eliminate a few misconceptions. Since Fauna does not provide a SQL interface, it is inevitably categorized as NoSQL along with the misconceptions that come along with that term. In contrast to what that term implies (depending on who you ask), Fauna actually is more similar to Postgres than many might think1.
The similarities:
- Use case: Both databases are aimed towards the same use case. In essence, they are both Online transaction processing (OLTP) databases. Overly simplified, it means that both excel at storing data that rapidly changes and is heavily read from without losing or corrupting data.
- ACID & Isolation levels: Both are ACID. In simple terms, data will not be out-of-date and your database will not suffer from a wide range of anomalies (1,2). The default isolation level in Postgres is read_committed, the highest level is serializable. Fauna’s default start isolation levels are stricter. The default starts at serializable while the highest level is strict serializable which is important in a distributed scenario.
- Relational: Both offer relations and ensure consistency across multiple tables/collections.
The differences:
- Relational-model vs Multi-model: Postgres is primarily built around the relational model but has additional data types to support documents (Json/Jsonb). Fauna is primarily a scalable relational document database. In contrast to many scalable databases, it does support flexible indexes which maintain consistency. Additionally, it adds temporality and some graph-like features such as graph traversal into the mix.
- Schema vs Schema-less: Postgres has a strong schema while, at the time of writing, Fauna is schemaless, improving developer flexibility without giving up the relational model. We will see how to deal with referential integrity and uniqueness concerns.
- Distribution & multi-region: When it comes to distribution in a traditional database, asynchronous replication is the most popular form of distribution which introduces eventual consistency and potential data loss. If consistency is required, synchronous replication is provided as an option, but it typically comes at a high price in terms of performance, especially if distribution across regions is desired. The high performance can be traced back to the algorithms used for distribution since traditional databases like Postgres were not built with distribution in mind. On the contrary, Fauna is built from the ground up as a scalable, multi-region distributed database. It is inspired by the Calvin algorithm that speeds up data consensus by relying on deterministic calculations. This manifests itself both in the design at its core as in the querying language as we will see later on.
- Language: Postgres provides SQL and has a query optimizer to select the right plan. Query optimization in Postgres can be a dark art, and query plans can change at runtime in surprising ways. In contrast to SQL, Fauna provides the Fauna Query Language (FQL) and native GraphQL. The choice for a custom language is rooted in the scalable and distributed design of Fauna. It’s designed to prevent long-running transactions, maximize performance in distributed scenarios, be highly composable to reduce round-trips and have a transparent and predictable query plan. While Fauna doesn't support SQL, this is something we might consider in the future.
- Database as an API: Postgres is an open-source database and is built to self-host (or to be hosted/managed by other cloud providers such as AWS RDS). Fauna is a transactional database delivered as an API. It is built to remove the need for development teams to think about maintenance and eliminate common operational tasks such as data partitioning and replication. For local development, there is a docker image provided.
- Database connections vs HTTP: Postgres connections are persistent, come with noticeable overhead and are limited in number which requires tools like PgBouncer in serverless scenarios. Fauna uses stateless, secure HTTP connections which requires no connection management.
Terminology mapping:
Before we start we will provide a brief overview of how Fauna concepts relate to Postgres concepts.
| Postgres | Fauna |
| Database | Database |
| Table | Collection |
| Row | Document |
| Index/View | Index |
| Stored Procedure/User Defined Function | User Defined Function (UDF) |
Tables and rows are collections and documents in Fauna just like in other document databases. An index in Fauna is a combination of an index and a view as we know them in a traditional database. We’ll directly query indexes for data since indexes contain data and are therefore very similar to consistent ordered views. User Defined Functions are similar to Stored Procedures except that in contrast to Postgres, both queries and UDFs are written in the same language in Fauna while in Postgres you would split to the PL/pgSQL language for a stored procedure. Fauna users typically use UDFs much more frequently due to the easy transition from a query to a UDF.
From DVD rental business to the next Netflix
A well-known Postgres tutorial provides a database model of a DVD rental business. The irony of scaling2 a DVD Rental business to modern cloud technologies is too enticing to ignore, so let us use it as our example.
The model of the DVD rental application looks as follows:
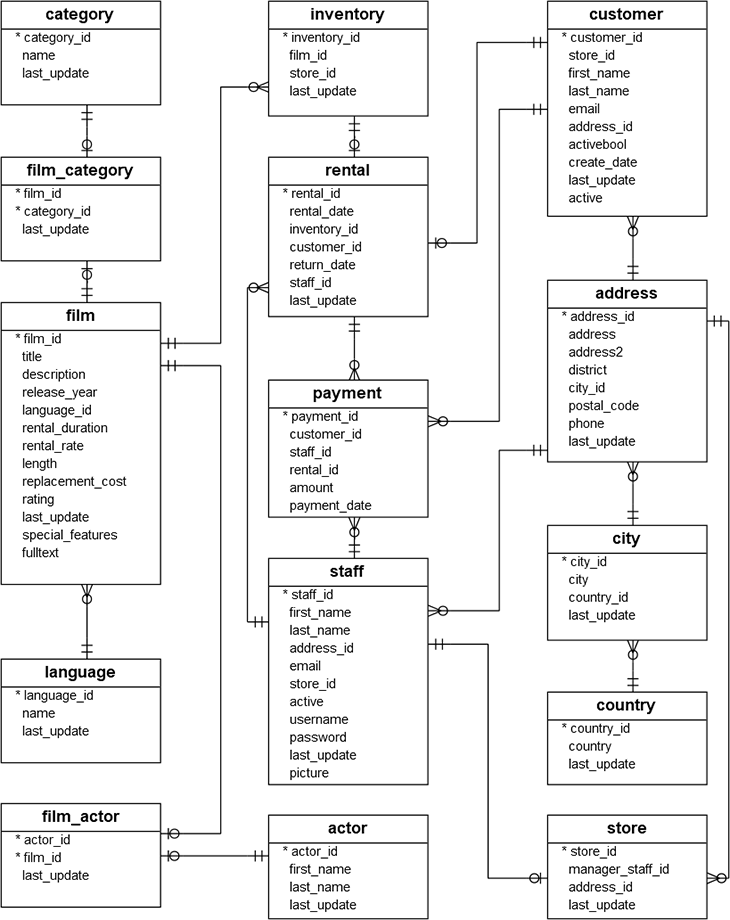
Source: PostgreSQL Tutorial - https://www.postgresqltutorial.com/postgresql-sample-database/
The database schema has “film" at its center and allows customers to rent DVDs from different stores around the country, supports shopping baskets (inventory), as well as film, payment, store and customer management. Thanks to the normalized model, it supports a plethora of access patterns: customers can find films by category, rating, release year, title, description, or actor. The staff can retrieve where a film currently resides or retrieve a list of overdue rentals.
Creating a new database
In this section, we’ll create the database. Even if you don’t follow along, this 2-click process (ok... plus typing a name) shows how different the database-creation process is compared to setting up a traditional database.
Sign up
Fauna is a cloud database, there is no setup of hardware or configuration necessary, all you need to do is go to dashboard.fauna.com and sign up for an account.
Create the database
Click NEW DATABASE to create a new database which will instantly be created.

Fill in a name and click SAVE

Now that you have created a database, you can follow along by pasting the provided code in the dashboard shell (or play around with the UI instead to create collections/indexes etc). Of course, you can also send queries to Fauna using one of the drivers or the terminal shell. The shell is built around the JavaScript driver behind the scenes. When writing FQL, we are not writing strings, but rather functions- although that might not be immediately clear when we use the dashboard shell.

You can create virtually as many databases as you want and can nest them inside other databases. This could be useful to make a database per environment, per developer, or even per integration test to simulate sandboxes.
Multiple databases or single database?
The realization that in Fauna, databases are lightweight and the ease of creating another database with the click of a button typically triggers the first question:
“Should we model our application data with multiple databases or keep all data in one database?”
In a traditional database which is not built to scale, we often move to a multi-database scenario for performance reasons. If your data no longer fits on disk, one solution would be to slice up the data and store it in multiple databases. However, this decision comes at a price since you can no longer execute transactions over the now separated datasets with conventional means. Although you can implement transactions over multiple databases yourself, one could call this an Inner-platform effect: reimplementing what the database does well on a higher level is probably inefficient and error-prone.
Since Fauna is a scalable database, the performance consideration of multiple databases becomes irrelevant. Because Fauna collections are built to scale, big collections will manifest similar performance as multiple Fauna databases with smaller collections. Nevertheless, Fauna’s concepts of lightweight databases and child databases make it extremely easy and appealing to use multiple databases. In some scenarios, it definitely makes sense to store your application data in multiple Fauna databases:
- You are following a microservice pattern for reason other than ‘the data layer rarely scales’.
- You are looking for an extra level of isolation
- Separate environments for different teams
- Isolation and parallelization of integration tests
- Purely to organize your data.
To decide, ask yourself whether you need transactions over the separate datasets or whether you need them to be completely isolated.
One-to-Many relations
Let’s start with a small (and easy) subset of the model and extend it gradually. The film and languages relations is a many-to-one relation which should be very easy to model. Since the model remains quite simple, we’ll add a few things now and then in green to render it more interesting. Instead of one language, we’ll add both a spoken and a subtitle language.
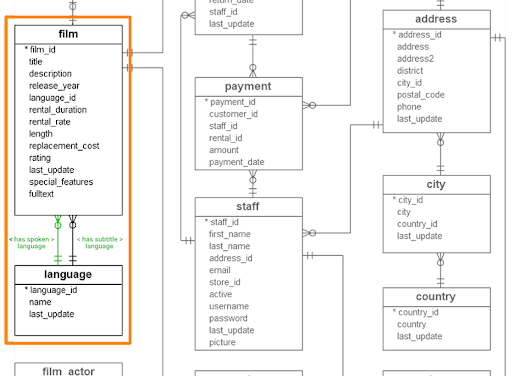
Creating the language collection
In Postgres, we have tables that contain rows; in Fauna, we have collections that contain documents. To create a new film collection, we could use the dashboard interface but just like in SQL, manipulation and creation of collections, indexes, security roles, or even databases can be done entirely in the query language. To create the film collection, we can also paste the following code snippet in the dashboard shell:
CreateCollection({name: "language"})Creating a language document
We can create the equivalent document for the language as follows:
Create(
Collection("language"),
{
data: {
name: "English"
}
}
)To create documents, the Create() function is used which is similar to an Insert statement in Postgres. It takes the collection where you want to store the document as a first parameter and a JSON object as the second. Application data is always nested under the data key which separates it from special Fauna fields. Once we have executed the Create() statement, we can take a look at the document by going to the Collections tab in the dashboard.
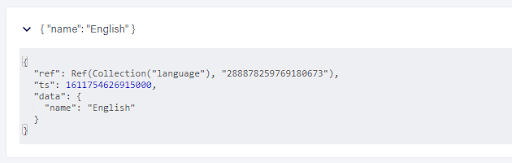
Fauna has automatically generated two fields: ref and ts which are the Fauna equivalent of id and last_update.
- ref: a unique reference to the document. The presence of references doesn’t mean that we can no longer use other IDs in Fauna. We’ll see the difference between native Fauna references and IDs shortly when we start querying.
- ts: the timestamp of the document which is automatically updated when the document is adapted. Fauna’s timestamp is part of temporality features which provide time-travel and support the streaming capabilities.
Creating the film documents
To store the film documents, we need a new collection:
CreateCollection({name: "film"})Let’s create a simplified film document. For the relation between films and languages, we actually have many potential choices (5 that I can think of immediately) since Fauna is both a document and relational database. However, anything that is not normalized is typically an optimization so let’s start with the normalized model.
We will make it slightly more interesting and add both a spoken language and the subtitles language. We will refer to the previously created language by storing the native reference in the document as follows:
Careful: Your reference ID will be different. If you are following along, you can grab the reference ID of any document from the dashboard's Collections view)
Create(
Collection("film"),
{
data: {
title: "Academy Dinosaur",
language: {
spoken: Ref(Collection("language"), "288878259769180673"),
subtitles: Ref(Collection("language"), "288878259769180673")
}
}
}
)An alternative approach is to add the languages as embedded objects. If we do not intend to efficiently query languages directly, we could opt to add it as an embedded object.
Create(
Collection("film"),
{
data: {
title: "Academy Dinosaur",
language: {
spoken: { name: "English" },
subtitles: { name: "English" }
}
}
}
)Embedding vs normalized data
Denormalization is not a workaround. It’s a choice.
Fauna is a document database which might make us think: “don’t join data, duplicate it” as popularized by several document databases. This is often a workaround due to design choices or limitations of the database. Since Fauna is relational, such workarounds are not a necessity but rather another option in your tool belt.
Postgres is not a document database but has a JSONB type which can be used to emulate documents. However, such columns do not benefit from the optimizations such as column statistics, are restricted to more primitive operations, lack built-in functions to modify values, and could feel awkward to query in SQL. The absence of column statistics essentially blinds the query planner, resulting in potential production issues. In light of these limitations, you might resort to storing frequently queried attributes in regular columns and the remainder in JSONB columns.
In contrast, Fauna's querying and indexing capabilities do not change based on whether documents contain nested data or normalized. That doesn’t mean that denormalization is the recommended practice, but it does become more attractive as a technique to optimize read performance. We’ll dive in some advanced optimization techniques at the end of this series and will show how FQL can actually help you hit the sweet spot between flexibility, optimization, and data correction.
Indexing works equally well on nested values and arrays
In some databases, indexing flexibility might suffer when nesting objects. However, Fauna’s indexing is built to be flexible regardless of whether the data is stored as nested objects or normalized. It works equally well on nested values or arrays, for example, we could index the spoken language by adding the following path **
data > language > spoken > name to the index. If spoken languages had been an array instead: {
data: {
title: "Academy Dinosaur",
language: {
spoken: [{ name: "English" }, { name: "French" }],
subtitles: { name: "English" }
}
}
}We can add the same path to the index and Fauna will recognize that it’s an array and unroll it. By using advanced features like index bindings we can even combine both the spoken and subtitles language in one index to find any film in a specific language, regardless whether it’s the spoken or subtitle language.
Before we talk about the trade-offs and even more alternative strategies, let’s see how we would retrieve films and then perform a simple join by including languages.
Querying one collection
Select IDs
The simplest Postgres query is very easy since SQL is a declarative language where you describe what you need instead of how you want it to be calculated.
SELECT id FROM filmIn contrast, FQL is a procedural language (like PL/pgSQL). Although it’s initially verbose we’ll see that we can easily extend the language to tame that verbosity.
The focus of this document is to replicate a traditional relational model in Fauna, which requires us to introduce some FQL. If this becomes overwhelming and you want to dive into the fundamentals of FQL, here is an excellent guide that starts from scratch and a guide to translate basic SQL queries to FQL.
Retrieving all documents starts by executing the Documents() function on a collection. The Collection() function returns the reference to the collection, and documents retrieves the film references from that collection.
Documents(Collection("film")) When executing this first query snippet, you might be surprised that it simply returns something like “ok, here is a reference to a set of films” but not the actual film documents yet.
{
"@set": {
documents: Collection("film")
}
}Just like SQL, FQL is inspired by relational algebra. In FQL, we construct sets. For example, we could combine the above statement with other sets using familiar functions such as Union(), Difference(), Distinct(). A set is merely a definition of the data we would like to retrieve but not a concrete dataset yet.
What is FQL?
Although it might seem like strings if we use the dashboard shell, we are actually using functions from the underlying JavaScript driver. Try misspelling a function in the dashboard shell, and you’ll get a familiar “<function> undefined” error. Or simply write:
var a = Documents(Collection("film"))
aMake sure to copy the whole statement at once. The Fauna dashboard shell does not maintain variables in between runs.
That JavaScript variable now contains our query definition, and we can use the variable to continue composing our query in a much more elegant way than string concatenation could allow. Many users take advantage of this to extend the language or construct their own DSL which we will show extensively in the rest of the article.
Pagination
To materialize a set and retrieve the data, it’s mandatory to call Paginate. Paginate as a mandatory construct is an important measure to ensure scalability and removes a potential gun to shoot oneself in the foot. By making pagination mandatory, transactions are always kept relatively small.
Paginate(Documents(Collection("film")))Which now returns a Page of film references:
{
data: [
Ref(Collection("film"), "288801457307648519"),
Ref(Collection("film"), "288877928042725889")
]
}Once we call Pagination, our set is transformed to a Page. The Data Types documentation Data Types documentation lists which functions can be called on Sets, Pages, Arrays, etc.
In case you added at least two films, we can add a size parameter to see the pagination in action. Fauna will return an after cursor to move to the next page.
Paginate(Documents(Collection("film")), {size: 1})
{
{
after: [Ref(Collection("film"), "288877928042725889")],
data: [Ref(Collection("film"), "288801457307648519")]
}
}We can then copy the after cursor to the get the next page.
Paginate(Documents(Collection("film")), {
size: 1,
after: [Ref(Collection("film"), "288877928042725889")]
})Data architects who have experimented with multiple ways of pagination within Postgres will probably want to know what kind of pagination this is. Fauna’s approach is close to the KeySet approach and cleverly takes advantage of snapshots to ensure that pages do not change when data is adapted. This is possible since everything we query in Fauna is backed by a sorted index. Just like Paginate, indexes are mandatory to avoid issuing unperformant queries.
Although we don’t seem to be using an index in the query above, Documents() is actually using a built-in index sorted by reference_. _By including pagination, the query above is actually more similar to the following query but with a superior form of pagination (the default page size is 64 in Fauna):
SELECT * FROM film
LIMIT 64Select *
In the previous queries, we only returned document references. To transform these references into the complete document data, we will loop over these references with the Map() FQL function, and call Get() on each of these references.
Map(
Paginate(Documents(Collection("film"))),
Lambda(["ref"], Get(Var("ref")))
) Besides Map and Get, we introduced Lambda and Var. Lambda is the FQL name for a simple anonymous function, which we can pass to Map to be executed on each element. Var is used to retrieve an FQL variable (in this case the parameter passed to Lambda).
“Can’t we simply retrieve the complete document directly instead of using Map?”
We can definitely do that by adding more values to the index, and we’ll extensively address the trade-offs when we talk about optimizations in the third article.
“What’s up with the Var and Lambda parameter syntax here?"
As mentioned before, we are essentially composing the query by calling JavaScript functions. Using strings like “ref” as variables, and retrieving them with Var(), helps keep JS variables separate from FQL variables. The advantages of writing your query by composing JavaScript functions lies in the extensibility. For example, we can extend FQL by writing a simple function that will be the equivalent of a simple Select * in SQL.
function SelectAll(name) {
return Map(
Paginate(Documents(Collection(name))),
Lambda(["ref"], Get(Var("ref")))
)
}
SelectAll("film")This composability allows you to use Fauna in ways that would be infeasible or incredibly hard in other databases, as we’ll see in optimization strategies. A prime example is the Fauna GraphQL query which compiles one-to-one to FQL maintaining the same database guarantees. This was relatively easy in Fauna, but requires advanced projects such as JOIN Monster in traditional databases.
After this function composition intermezzo, let’s get back to work writing more advanced queries and modeling more complex relations.
Querying a one-to-many relation
Querying embedded documents
If we had embedded the language document by storing the languages directly in the film document, we would not have to change the query, simply returning the film documents would include the languages.
Map(
Paginate(Documents(Collection("film"))),
Lambda(["ref"], Get(Var("ref")))
) Retrieving the film document with** **Get() would immediately return the complete document including the languages.
{
ref: Ref(Collection("film"), "289321621957640705"),
ts: 1612177450050000,
data: {
title: "Academy Dinosaur",
language: {
spoken: {
name: "English"
},
subtitles: {
name: "English"
}
}
}
}Querying normalized data with native references
However, remember that we chose to store references instead of embedding the documents.
{
data: {
title: "Academy Dinosaur",
language: {
spoken: Ref(Collection("language"), "288878259769180673"),
subtitles: Ref(Collection("language"), "288878259769180673")
}
}
}This means that we need to write the equivalent of a Postgres join. In Postgres, that would look as follows:
SELECT * FROM film
JOIN "language" as spol ON spol.language_id = film.spoken_language_id
JOIN "language" as subl ON subl.language_id = film.subtitles_language_id
LIMIT 64In Postgres, we define the join we would like to see and rely on the query optimizer to select the right algorithm. If the query optimizer makes a wrong judgement, query performance can suffer significantly. Depending on the data and the way we are joining, the join algorithm could differ and could even change when the size of the data changes.
Due to the scalable nature of Fauna, we need predictability, both in terms of price and performance. We have talked about set functions such as Union(), Difference(), Distinct() but counterintuitively we won’t use a Join statement in Fauna. Although joins can scale, it depends on many factors. To ensure predictability, we’ll join on the materialized documents after pagination. We’ll retrieve the film document within the lambda and paginate on each level as we’ll see when we tackle many-to-many joins.
We’ll continue building upon the previous query which returns our film documents with language references.
Map(
Paginate(Documents(Collection("film"))),
Lambda(["ref"], Get(Var("ref")))
) First, we'll slightly refactor it to bind variables with Let(), which will bring more structure to our queries and render them more readable. Within a Let(), we can then retrieve anything related to a film that we desire.
Map(
Paginate(Documents(Collection("film"))),
Lambda(["filmRef"],
Let({
film: Get(Var("filmRef"))
},
// for now, we just return the film variable.
Var("film")
))
)And then, we retrieve both language references from the film document with Select() and get the actual languages by dereferencing the spoken and subtitles language reference with Get().
Map(
Paginate(Documents(Collection("film"))),
Lambda(["filmRef"],
Let({
film: Get(Var("filmRef")),
spokenLang: Get(Select(['data', 'language', 'spoken'], Var("film"))),
subLang: Get(Select(['data', 'language', 'subtitles'], Var("film")))
},
// todo
)
)
)And finally, return these variables in the structure we prefer.
Map(
Paginate(Documents(Collection("film"))),
Lambda(["filmRef"],
Let({
film: Get(Var("filmRef")),
spokenLang: Get(Select(['data', 'language', 'spoken'], Var("film"))),
subLang: Get(Select(['data', 'language', 'subtitles'], Var("film")))
},
// return a JSON object
{
film: Var("film"),
language: {
spoken: Var("spokenLang"),
subtitles: Var("subLang")
}
})
)
)The result is a nicely structured result with the film and both languages.
{
data: [
{
film: {
ref: Ref(Collection("film"), "288980003744383489"),
ts: 1611851657590000,
data: {
title: "Academy Dinosaur",
language: {
spoken: Ref(Collection("language"), "288878259769180673"),
subtitles: Ref(Collection("language"), "288878259769180673")
}
}
},
language: {
spoken: {
ref: Ref(Collection("language"), "288878259769180673"),
ts: 1611754626915000,
data: {
name: "English"
}
},
subtitles: {
ref: Ref(Collection("language"), "288878259769180673"),
ts: 1611754626915000,
data: {
name: "English"
}
}
}
}
]
}Querying normalized data with regular IDs
In the above example, we had access to language references in the film document. Therefore, we could directly use Get() to dereference these references. What if we had chosen user-defined primary keys instead of Fauna references? For example:
Create(
Collection("film"),
{
data: {
title: "Academy Dinosaur",
language: {
spoken: 6,
subtitles: 6
}
}
}
)
Create(
Collection("language"),
{
data: {
id: 6,
name: "English"
}
}
)Fauna is still able to retrieve the languages, but it would require an extra step with an index. For the sake of comparison, let’s implement the same query. First, we need an index to retrieve the languages by id:
CreateIndex({
name: "language_by_id",
source: Collection("language"),
terms: [
{
field: ["data", "id"]
}
],
values: [
{
field: ["ref"]
}
]
})The main ingredients of indexes in Fauna are terms and values. Terms determine what the index matches on, while values determine what it returns (and in what order). Since indexes return values in Fauna, they are a mix of a view and an index as we know them in Postgres. In fact, we can significantly optimize our queries with indexes once we know the access patterns (as we’ll explain later). In this case, we’ll start in a generic fashion and only return the language reference from the index.
We’ll call the index with the Match() function. As long as we only need the first result from Match, we can call Get on the match. We will see how to handle multiple results later on.
Map(
Paginate(Documents(Collection("film"))),
Lambda(["filmRef"],
Let({
film: Get(Var("filmRef")),
spokenLangId: Select(['data', 'language', 'spoken'], Var("film")),
subLangId: Select(['data', 'language', 'subtitles'], Var("film")),
spokenLang: Get(Match(Index("language_by_id"), Var("spokenLangId"))),
subLang: Get(Match(Index("language_by_id"), Var("subLangId"))),
},
// and return the values however you want.
)
)
)Native Fauna references or user-defined IDs?
Both! Fauna's native references will not only simplify your code, but retrieve data in a more efficient way (similar to what graph databases call index-free-adjacency).
And you can set your own custom IDs within Fauna's native references during document creation:
Create(
Ref(Collection('language'), '6'),
{ name: { title: 'English' } },
)Conclusion
We’ve shown how to start querying basic relations, discussed some trade-offs, and presented a brief introduction to FQL. In the next chapter, we’ll dive into more complex relations with association tables and many-to-many relations. We’ll dive into advanced joins and explain how they are done differently in Fauna. In the final chapter, we’ll dive into optimization techniques, constraints, and tips to ensure data integrity in a schemaless database.
Note
Many applications might not need scale and premature optimization is the root of all evil. However, many are aiming to build the next software as a service which can become big at any given point in time. In that case, the idea that one should postpone the scalability of your data layer until it’s needed is arguably flawed. Is the moment that your application gains significant traffic really the best time to start a delicate operation and switch out the database with a scalable one? What if building it scalable is just as easy?
If you enjoyed our blog, and want to work on systems and challenges related to globally distributed systems, serverless databases, GraphQL, and Jamstack, Fauna is hiring!
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.